./articles/ GenAI and LLM Questions with In-Depth Answers
The rapid advancements in Generative AI and Large Language Models (LLMs) have brought transformative changes to industries ranging from customer support to creative content generation. As organizations and professionals dive into this exciting domain, understanding the key concepts and gaining practical knowledge is crucial.
This guide serves as a comprehensive resource for anyone preparing for interviews or aiming to deepen their expertise in LLMs. Each topic is composed of a wide range of questions, carefully curated to cover foundational concepts, practical applications, and advanced topics. The questions in this guide are derived from the repository LLM Interview Questions, a community-driven resource dedicated to fostering knowledge and preparation in the field of LLMs.
The questions tackle diverse areas such as Prompt Engineering and Basics of LLM, exploring foundational principles like understanding predictive vs. generative AI, key concepts in language model training, and decoding strategies, as well as advanced aspects like in-context learning and strategies to optimize prompt writing for enhanced model performance. These topics highlight not only theoretical knowledge but also practical approaches to improving the reasoning and utility of LLMs across varied use cases.
Quick Navigation
1. Basics of LLM
1.1 What is the difference between Predictive/Discriminative AI and Generative AI?▼
Predictive AI, also known as discriminative AI, focuses on predicting the output based on input data. It aims to learn the relationship between input features and output labels, making predictions based on patterns in the training data. Common examples of predictive AI include classification and regression tasks, where the model predicts discrete classes or continuous values, respectively.
Core Characteristics:
- Focuses on learning \(P(y|x)\) - the probability of output y given input x
- Optimized for accuracy in classification and prediction tasks
- Efficient in resource usage compared to generative models
- Typically requires less training data for good performance
- Better suited for tasks with clear decision boundaries
Key Technical Aspects of Predictive AI you must known:
- Feature Engineering: The process of manually or automatically deriving meaningful features from raw data to improve model performance.
- Loss Functions: Metrics used to quantify prediction errors, including cross-entropy, hinge loss, and mean squared error (MSE).
- Optimization: Techniques such as gradient descent and stochastic optimization to minimize the loss function during training.
- Regularization: Methods like L1/L2 regularization, dropout, and batch normalization to prevent overfitting and improve generalization.
Generative AI, on the other hand, is designed to generate new data that resembles the training data distribution. Instead of predicting a specific output, generative models learn the underlying structure of the data and generate new samples that are similar to the training examples. These models can create new images, text, audio, or other types of data based on the patterns they have learned during training.
Core Characteristics:
- Models the complete joint probability distribution \(P(x,y)\)
- Creates novel, coherent outputs across various domains
- Can handle multiple tasks including content generation and understanding
- Requires larger datasets and computational resources
- Capable of unsupervised and self-supervised learning
Key Examples of GenAI Architectures to know:
- Transformer Models: Use self-attention mechanisms, which allow the model to weigh the importance of different words in a sentence, and multi-head attention, which enables the model to focus on different parts of the sentence simultaneously for better context understanding.
- Generative Adversarial Networks (GANs): Utilize a generator, which creates data samples, and a discriminator, which evaluates them, in a competitive framework to create realistic data samples.
- Diffusion Models: Use denoising processes, which iteratively refine noisy data to generate high-quality outputs, and U-Net architectures, which are convolutional neural networks designed for image segmentation and generation.
- Variational Autoencoders (VAEs): Focus on latent space modeling using the reparameterization trick, which allows for backpropagation through stochastic variables by introducing a differentiable approximation, and minimize reconstruction loss for generative tasks.
1.2 What is LLM, and how are LLMs trained?▼
LLM (Large Language Model) is an AI system trained to understand and generate human-like text by processing vast amounts of textual data. These models represent the cutting edge of natural language processing technology.
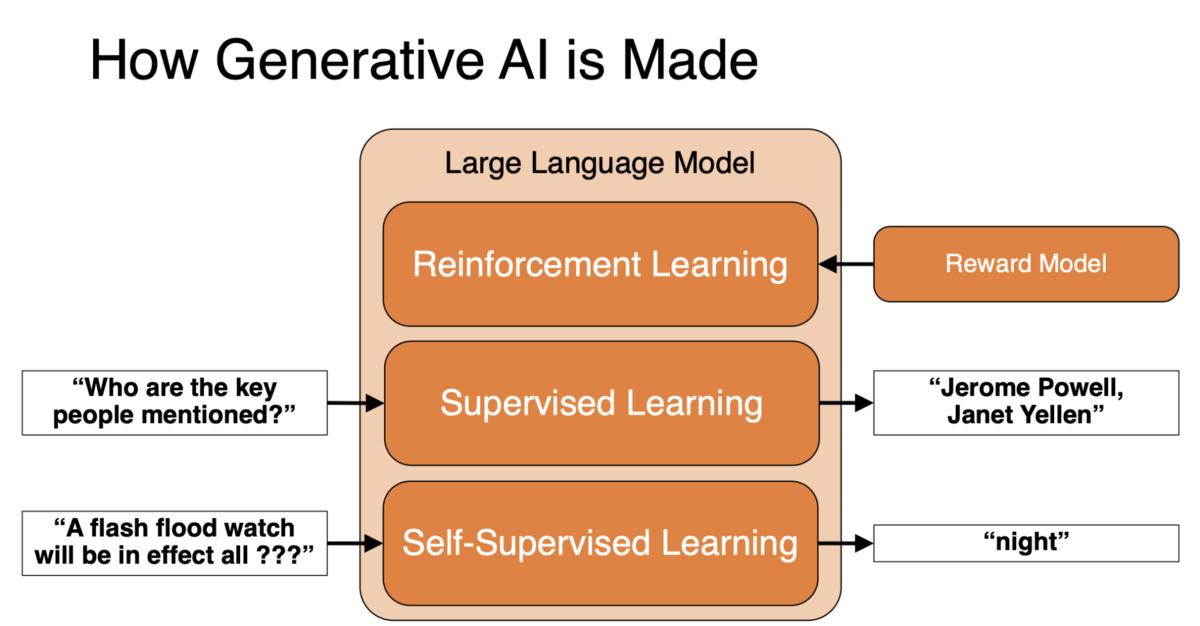
Training large language models is a multi-layered stack of processes, each playing a unique role in shaping the model's performance. The three main phases are:
- Self-supervised learning
- Supervised learning
- Reinforcement learning
Phase 1: Self-Supervised Learning for Language Understanding
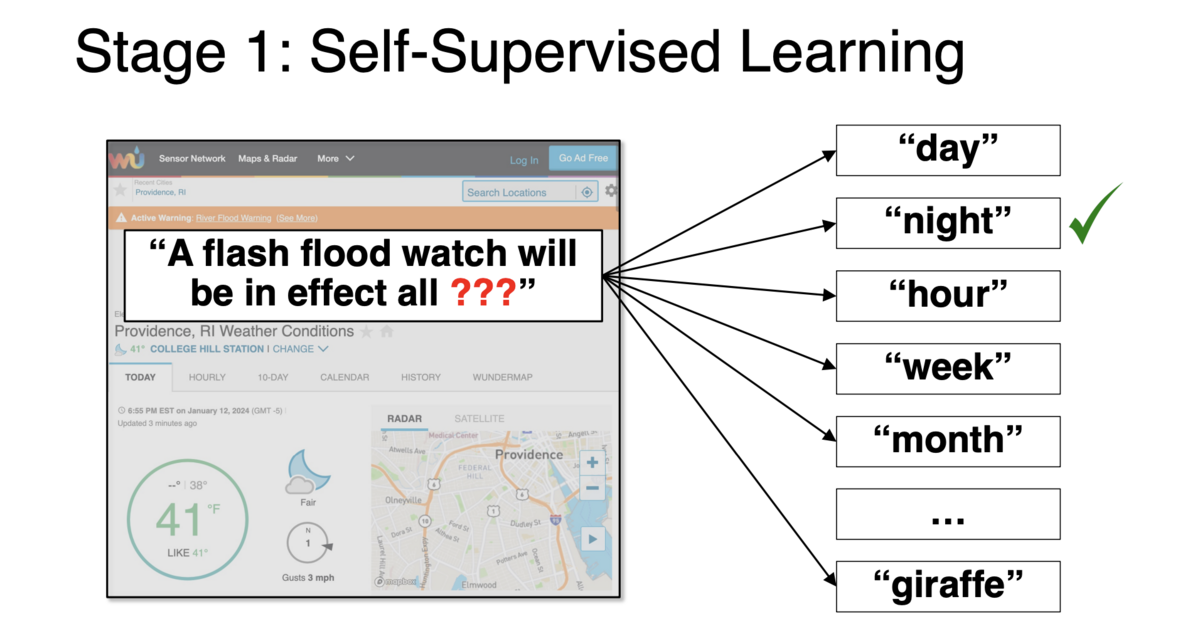
Self-supervised learning, the first phase of training, is typically what comes to mind when discussing language modeling. This process involves exposing the model to vast amounts of unannotated or raw data and instructing it to predict the ‘missing’ elements within that data. Through this, the model learns about both language and the underlying domain to generate plausible responses.
For instance, if we provide the model with text from a weather website and ask it to predict the next word, the model must comprehend the language and the context of the weather domain. In my presentation, I used the example: “A flash flood watch will be in effect all _____.” At an intermediate stage, the model ranks possible predictions, from the most likely answers (“day,” “night,” “hour”) to those that are less probable (“month”), and even to nonsensical ones (“giraffe”) that receive low probability scores.
This process is called self-supervision (distinct from unsupervised learning) because there is a specific, correct answer—the word that appeared in the collected text, which in this case was “night.” While self-supervision shares similarities with unsupervised learning, it is distinct in that it focuses on predicting specific correct outcomes, even within the context of abundant, unannotated data.
Phase 2: Supervised Learning for Instruction Understanding
Supervised learning, or instruction tuning, marks the second stage in the training process of large language models (LLMs). This phase is vital, building upon the foundational knowledge established during the self-supervised learning phase. In this phase, the model is trained specifically to follow instructions. Unlike self-supervised learning, which focuses on predicting words and completing sentences, instruction tuning teaches the model to understand and respond to explicit user requests. This shift makes the model significantly more interactive and useful in real-world applications. The impact of instruction tuning on enhancing LLM capabilities has been demonstrated through numerous studies, including those led by Snorkel researchers. One key outcome was that models trained with instruction tuning performed better at generalizing to new, unseen tasks. This is a major achievement, as the ability to effectively handle unfamiliar tasks is a central goal of machine learning models. Given its proven success, instruction tuning has become a standard practice in LLM training. Once this phase is completed, the model is no longer just predicting the next word—it’s trained to engage with users, comprehend their instructions, and provide meaningful, context-aware responses.
Phase 3: Reinforcement Learning to Promote Desired Behavior
The final stage in training large language models (LLMs) is reinforcement learning, a critical process that fine-tunes the model by encouraging desired behaviors and discouraging undesirable outputs. Unlike earlier stages, this phase doesn’t provide the model with specific target outputs but instead evaluates and “grades” the responses the model generates.
Although reinforcement learning has a long history in machine learning, its application to LLM training was first proposed by OpenAI after the advent of instruction tuning. The process begins with a model already capable of understanding instructions and generating coherent language. Human annotations are then used to compare model outputs, identifying which responses are better or worse. These comparisons help guide the creation of a reward model, which assigns quantitative scores to the quality of the outputs. The reward model plays a pivotal role by scaling feedback to the model, steering it toward generating preferred responses while penalizing undesired ones. This method is particularly effective for fostering nuanced behaviors, such as encouraging brevity or discouraging harmful or inappropriate language. As a result, the model learns to produce higher-quality, context-sensitive responses.
This process, known as reinforcement learning with human feedback (RLHF), underscores the value of human involvement in shaping the model's behavior. By incorporating human preferences into the training loop, RLHF ensures the model aligns more closely with user expectations and ethical standards, delivering a safer and more user-centric experience.
1.3 What is a token in the language model?▼
In the context of language models, a token refers to the smallest unit of text that the model processes. Tokens can represent individual words, subwords, or characters, depending on the tokenization strategy used. The choice of tokenization impacts the model's ability to understand and generate text.
Each language model has a context window—a limit on the number of tokens it can handle at a time. This context window defines how much text the model can "remember" and process simultaneously. For example, a model with a 4,000-token context window can work with approximately 3,000–4,000 words of text at once, depending on the complexity of the language and the average token length.
The vector representation of a token is called an embedding. These vectors capture the meaning, context, and relationships between tokens in a form that the model can compute.
1.4 How to estimate the cost of running SaaS-based and Open Source LLM models?▼
These are subscription-based or pay-per-use services that provide hosted LLMs. SaaS-based LLM services charge based on processed tokens (both input and output). For example, GPT-4 charges $0.03 for input tokens and $0.06 for output tokens per 1,000 tokens. The total cost can be calculated by multiplying the sum of input and output tokens by the cost per token.
Total Cost = (Tokens Input + Tokens Output) × Cost Per Token
Other costs include compute tier options (with different pricing for different models), monthly subscription fees for premium access, and possible additional charges for reserved capacity to ensure low latency or scalability.
With SaaS, there’s no need for infrastructure setup or maintenance. The service scales automatically, making it ideal for prototypes or low-volume usage.
On the other hand, Open Source LLM models are free to use but require infrastructure setup and maintenance. For self-hosted open-source models, compute costs can vary widely depending on the choice of infrastructure. Cloud-based GPU instances range from $1 to $6 per hour per GPU, with an average cost for an NVIDIA A100 instance being around $2.5 per hour. The compute cost is calculated by multiplying the instance cost by the number of hours used.
Cost (Compute) = (Instance Cost) × (Hours of Use)
Open-source LLMs also incur storage and networking costs (e.g., 100GB+ for large models), energy costs for continuous operation, personnel costs for engineering and maintenance, and possible software licensing fees for supporting software.
Open source LLMs offer full control over the model and infrastructure. They can be customized for specific needs and may incur lower long-term costs for high-volume usage.
Comparison table
| Factor | SaaS-Based | Open-Source |
|---|---|---|
| Ease of Setup | Instant, minimal configuration | Significant setup and maintenance |
| Scalability | Automatic, scales with need | Manual provisioning required |
| Costs for Low Usage | Lower for prototypes | Higher initial setup cost |
| Costs for High Usage | Scales linearly, can be expensive | More cost-effective long-term |
| Customizability | Limited by vendor | Full control |
| Operational Control | Relies on vendor | Complete independence |
1.5 Explain the Temperature parameter and how to set it.▼
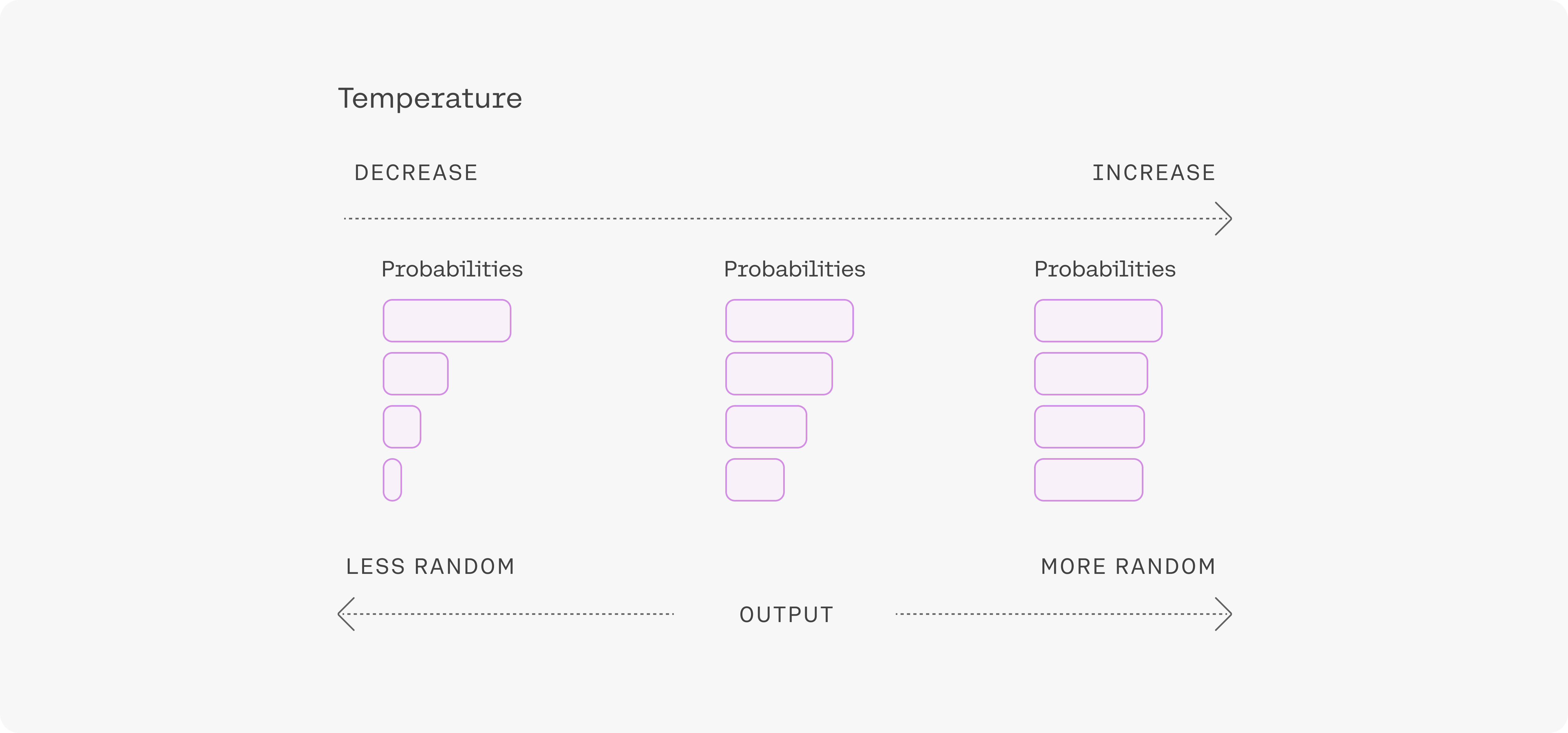
The Temperature parameter is used in language models to control the level of randomness in the text generation process. It is particularly useful for fine-tuning the creativity and variability of the model’s responses.
In simple terms, the temperature adjusts the "steepness" of the probability distribution over possible next words or tokens. When generating text, a model selects tokens based on a distribution of probabilities. A lower temperature (e.g., 0.1) makes the model more deterministic, meaning it is more likely to select the most probable next token, leading to more predictable and coherent text. A higher temperature (e.g., 1.0) adds more randomness to the selection, allowing for more creative or unexpected outputs.
The temperature parameter works by modifying the logits (raw scores) of the possible next tokens before converting them to probabilities using the softmax function. The formula for calculating the probability distribution for the next token given the logits is:
\[P(w_i) = exp(logit(w_i) / T) / Σ exp(logit(w_j) / T) \]
Here, \(w_i\) refers to the ith token in the vocabulary, and \(logit(w_i)\) is the unscaled score for that token. The parameter T is the temperature:
- T = 0: This means maximum determinism. The model always selects the most probable token (argmax sampling). However, most implementations prevent using an exact 0 since it removes any stochasticity altogether.
- T between 0 and 1: Sharper probability distributions, making high-probability tokens even more dominant. Lower values reduce randomness and make the output more focused and predictable.
- T = 1: No adjustment to the logits. The original probability distribution is used.
- T > 1: Flattens the probability distribution, increasing randomness. Less probable tokens become more likely to be chosen, producing creative or exploratory outputs.
The temperature parameter is often adjusted through an API or in the model configuration. If you are interacting with an API, you will usually specify the temperature in the request. Here's a typical API call setting:
{
"model": "gpt-4",
"temperature": 0.7,
"prompt": "Describe a sunset over a mountain range."
}
Experimenting with different temperature settings can help achieve the desired tone and level of creativity in the responses. Lower temperatures are appropriate for factual, straightforward tasks, while higher temperatures are useful for generating new ideas, brainstorming, or creative writing.
1.6 What are different decoding strategies for picking output tokens?▼
Language models are pre-trained to predict the next token in a text corpus. Decoding strategies determine how to select the next token based on the probability distribution over a fixed vocabulary. The process of selecting these tokens, known as decoding, plays a crucial role in shaping the output text. By tailoring the decoding approach, you can customize text generation to suit specific needs. Depending on the decoding method, the model may choose the most probable token, consider multiple top candidates, or introduce randomness for variety.
An effective decoding strategy transforms a language model from a simple next-token predictor into a powerful text generator capable of handling diverse tasks. This raises two key questions: "What are the different decoding strategies?" and "How do they influence the output generated by language models?".
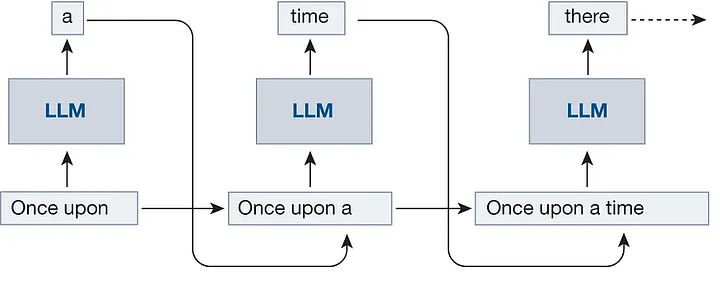
The simplest way to implement a sampling function is to select the next token with the highest probability at each step, an approach known as Greedy Search. This straightforward method is fast and efficient because it prioritizes the most probable token every time. However, this predictability often results in repetitive or unoriginal text, making it unsuitable for generating creative content. Can this be improved? Absolutely.
Beam search offers an enhancement by maintaining a beam of the K most probable sequences at each time step, where K is the beam width. The process continues until a maximum sequence length is reached or an end-of-sequence token is generated. Beam search typically results in higher-quality text than greedy search, but it requires more computational effort.
Suppose the initial sequence is "Once upon a time" and K=2.
- The two most likely tokens are "a" and "the".
-
In the next step:
-
The sequence ("a", "cat") has a probability of
0.20 (
0.5 × 0.4). -
The sequence ("the", "people") has a probability of
0.21 (
0.3 × 0.7).
-
The sequence ("a", "cat") has a probability of
0.20 (
- Beam search selects the sequence "the people" as it has the higher cumulative probability.
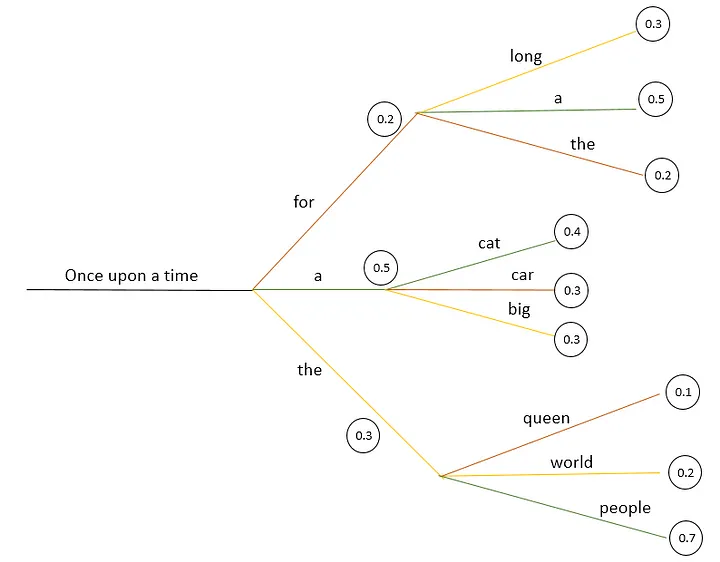
The above methods that choose the most probable next token at each step are called Deterministic methods. These methods produce output text ensuring predictability but often at the expense of diversity. So if you are looking for creative writing, we need some better mechanisms.
To overcome the limitations of deterministic methods in generating varied and creative text, stochastic methods introduce randomness into the selection process. These methods reduce predictability, creating outputs that are less repetitive and more diverse.
When generating text, stochastic methods often rely on strategies that prioritize tokens with higher probabilities while maintaining a degree of randomness. Popular approaches for achieving this balance are ramdom sampling, temperature sampling, Top-k sampling and Top-p sampling, each offering unique mechanisms for selecting the next token.
The simplest stochastic approach is random sampling, where the next token is sampled from the probability distribution:
def sample(p):
return np.random.choice(np.arange(p.shape[-1]), p=p)
With this method, each execution produces different outputs. However, while less predictable, this approach may result in incoherent text. To achieve varied yet coherent results, we need more refined strategies.
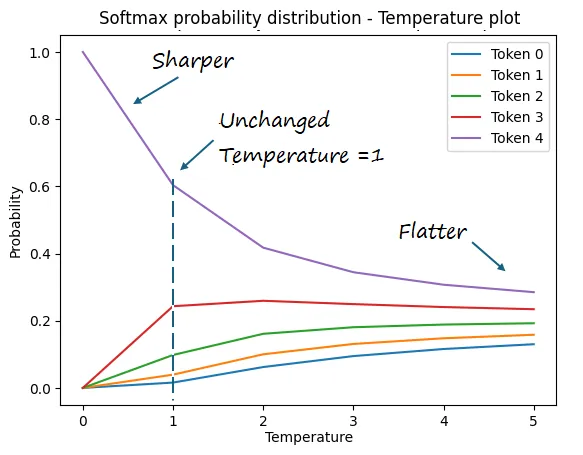
Temperature sampling, as discuss earlier, adjusts the likelihood of selecting tokens by altering the temperature of the softmax function, which transforms the model’s logits into probabilities.
Consider tokens with logits [1, 2, 3, 4, 5]. The following code plots the temperature-controlled softmax probability distribution:
from matplotlib import pyplot
import torch
depth = range(6)
logits = torch.tensor([1, 2, 3, 4, 5])
prob_list = []
for temperature in depth:
prob = torch.nn.functional.softmax(logits / (temperature + 0.1), dim=-1)
prob_list.append(prob.numpy())
pyplot.plot(depth, prob_list)
pyplot.xlabel("Temperature")
pyplot.ylabel("Probability")
pyplot.title("Temperature-Controlled Softmax Distribution")
pyplot.show()
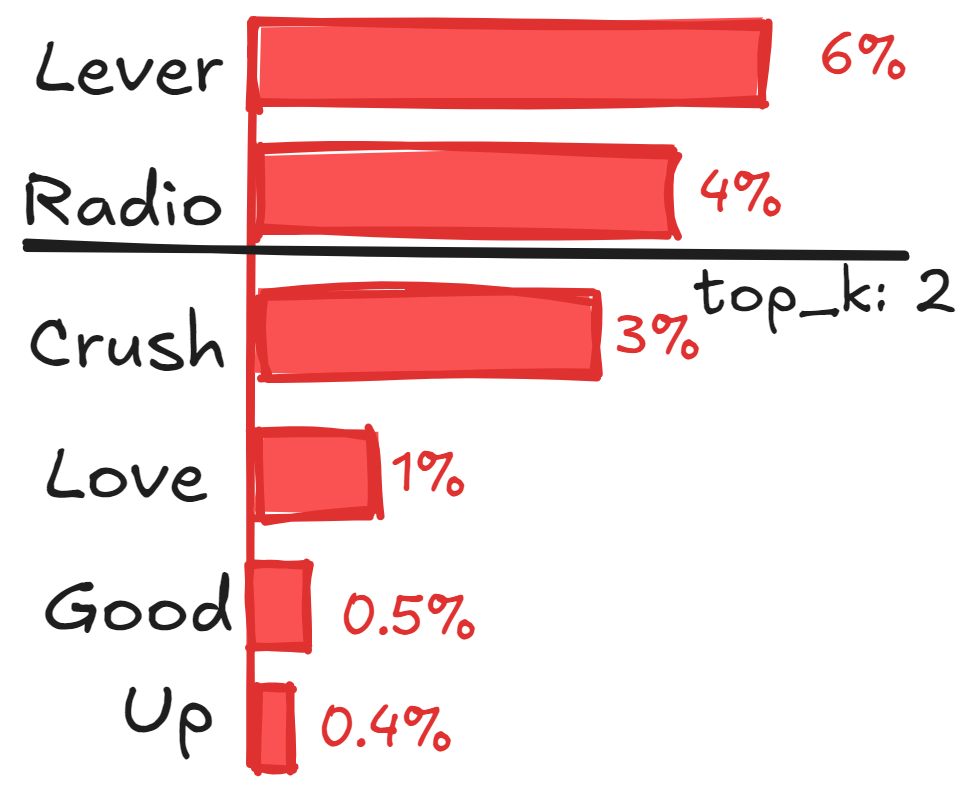
Top-k sampling limits selection to the k most probable tokens. For instance, if k=2 and token probabilities are:
\( P(T_0) = 0.6, P(T_1) = 0.4, P(T_2) = 0.3, P(T_3) = 0.1, P(T_4) = 0.05, P(T_5) = 0.04 \)
The tokens \( T_3, T_4, T_5 \) are excluded, and the remaining probabilities are redistributed.
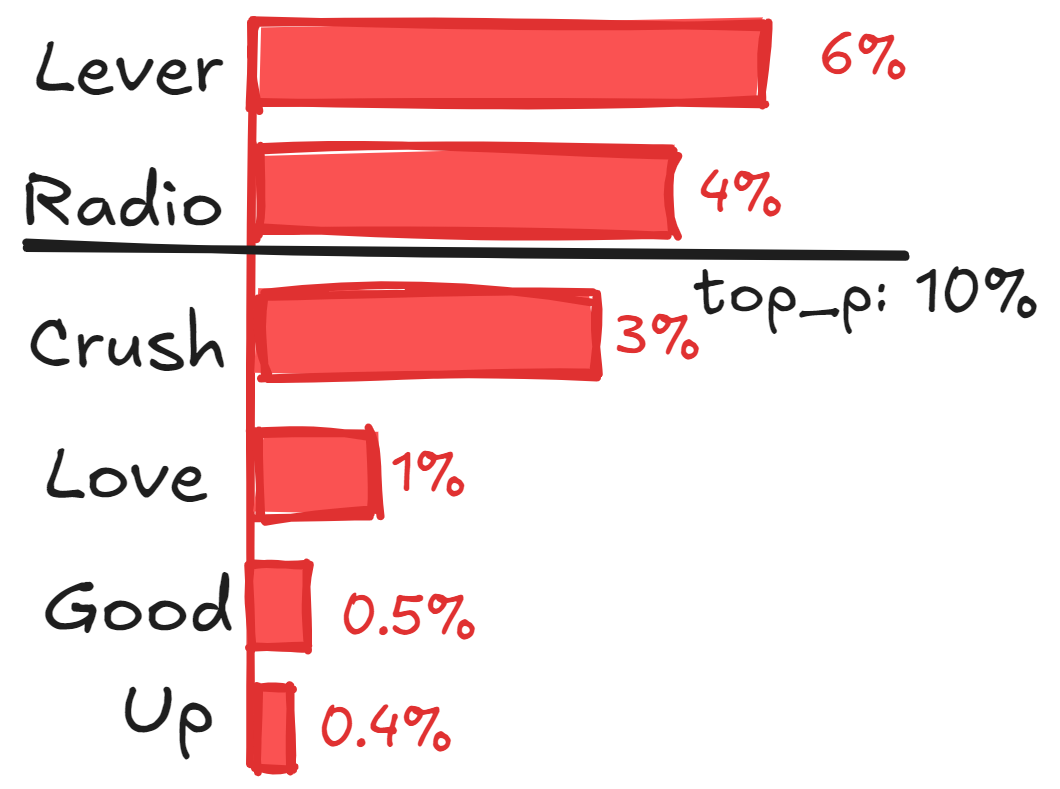
Top-p Sampling — chooses from the possible set of words whose cumulative probability exceeds the probability p. The probability mass is then redistributed among this set of words. For p = 0.95, Top-p sampling picks the minimum number of tokens to exceed together p = 95% of the probability mass. Unlike Top-k sampling which has a fixed number of tokens k, this mechanism allows the number of tokens in a set to dynamically increase or decrease according to the next word’s probability distribution. Choosing a set of high-probability tokens removes the very unlikely low-probability values, thus helping to generate diverse and coherent text, making it very popular for text generation. This Top-p sampling is also known as Nucleus sampling.
Combining top-p and top-k sampling can further refine the balance between randomness and coherence.
1.7 What are different ways you can define stopping criteria in large language model?▼
One common approach is to set a predefined token limit. By specifying the maximum length of the output, we can ensure that the generated text doesn’t exceed a certain number of tokens. This is particularly useful in cases like generating headlines or summaries where brevity is essential. For more structured tasks, minimum and maximum length thresholds can be combined. This ensures the output is neither too short to be meaningful nor too long to remain concise. For example, when generating summaries, you might require the output to be at least 30 tokens but no more than 100 tokens long.
response = model.generate(input, min_length=30, max_length=100)
Another widely used technique involves relying on the end-of-sequence (EOS) token. The model generates tokens until it predicts this special token, which signals that the sequence has concluded naturally. This method is ideal for scenarios like document generation or conversational models, where the model's training data inherently includes a concept of when sequences should terminate.
if token == eos_token:
break
To prevent outputs from becoming repetitive or looping endlessly, a repetition-based stopping criterion or frequency penalty is often applied. This involves checking the sequence of tokens generated so far and ending the process if significant repetition is detected.
if sequence in history:
break
In dynamic and real-time applications like chatbots, a time-based stopping criterion might be more appropriate. Here, the model ceases generation once a specified duration has passed. This ensures timely responses and enhances the interactive experience for users.
Another advanced approach involves semantic analysis. Instead of setting hard rules based on token counts or repetition, the model evaluates the coherence and relevance of its generated tokens. If the semantic quality drops below a specific threshold, the generation is stopped. Probabilistic methods can also guide stopping criteria. For instance, by monitoring the probabilities associated with predicted tokens, you could stop when the highest-probability token falls below a certain threshold, indicating that the model is uncertain. This method is useful in precision-critical tasks.
In many cases, a combination of criteria yields the best results. For example, combining a token limit, EOS token detection, and repetition-based stopping can create robust rules for most tasks.
1.8 How to use stop sequences in LLMs?▼
Once you've defined the stop sequence, you'll typically pass it as a parameter when making the request to generate text from an LLM API.
If you’re using OpenAI's API to generate text, you can specify the stop parameter in the API request.
import openai
response = openai.Completion.create(
engine="text-davinci-003", # The model to use
prompt="Please write a creative ending for Dragon Ball.", # The text prompt
stop=["END", "===END==="], # List of stop sequences to terminate the generation
max_tokens=100 # Limit the maximum number of tokens (words/pieces of text)
)
print(response.choices[0].text.strip())
2. Prompt Engineering
2.1 Explain the basic structure of prompt engineering.▼
Effective prompting can unlock the full potential of large language models (LLMs). While simple prompts can yield results, the quality of the output improves with well-crafted instructions and sufficient context.
A prompt contains any of the following elements:
- Instruction - a specific task or instruction you want the model to perform
- Context - external information or additional context that can steer the model to better responses
- Input Data - the input or question that we are interested to find a response for
- Output Indicator - the type or format of the output.
To demonstrate the prompt elements better, here is a simple prompt that aims to perform a text classification task:
Prompt: Classify the text into neutral, negative, or positive Text: I think the food was okay. Sentiment:
In the prompt example above, the instruction corresponds to the classification task, "Classify the text into neutral, negative, or positive". The input data corresponds to the "I think the food was okay." part, and the output indicator used is "Sentiment:". Note that this basic example doesn't use context but this can also be provided as part of the prompt. For instance, the context for this text classification prompt can be additional examples provided as part of the prompt to help the model better understand the task and steer the type of outputs that you expect. You do not need all four elements for a prompt and the format depends on the task at hand. We will touch on more concrete examples in upcoming guides.
As you get started with designing prompts, you should keep in mind that it is really an iterative process that requires a lot of experimentation to get optimal results. Using a simple playground from OpenAI or Cohere is a good starting point. You can start with simple prompts and keep adding more elements and context as you aim for better results. Iterating your prompt along the way is vital for this reason. As you read the guide, you will see many examples where specificity, simplicity, and conciseness will often give you better results. When you have a big task that involves many different subtasks, you can try to break down the task into simpler subtasks and keep building up as you get better results. This avoids adding too much complexity to the prompt design process at the beginning.
You can design effective prompts for various simple tasks by using commands to instruct the model what you want to achieve, such as "Write", "Classify", "Summarize", "Translate", "Order", etc. Keep in mind that you also need to experiment a lot to see what works best. Try different instructions with different keywords, contexts, and data and see what works best for your particular use case and task. Usually, the more specific and relevant the context is to the task you are trying to perform, the better. We will touch on the importance of sampling and adding more context in the upcoming guides. Others recommend that you place instructions at the beginning of the prompt. Another recommendation is to use some clear separator like "###" to separate the instruction and context.
Prompt:
### Instruction ###
Translate the text below to Spanish:
Text: "hello!"
Output: ¡Hola!
Be very specific about the instruction and task you want the model to perform. The more descriptive and detailed the prompt is, the better the results. This is particularly important when you have a desired outcome or style of generation you are seeking. There aren't specific tokens or keywords that lead to better results. It's more important to have a good format and descriptive prompt. In fact, providing examples in the prompt is very effective to get desired output in specific formats. When designing prompts, you should also keep in mind the length of the prompt as there are limitations regarding how long the prompt can be. Thinking about how specific and detailed you should be. Including too many unnecessary details is not necessarily a good approach. The details should be relevant and contribute to the task at hand. This is something you will need to experiment with a lot. We encourage a lot of experimentation and iteration to optimize prompts for your applications.
Prompt:
Extract the name of places in the following text.
Desired format:
Place: <comma_separated_list_of_places>
Input: "Although these developments are encouraging to researchers, much is still a mystery.
“We often have a black box between the brain and the effect we see in the periphery,” says
Henrique Veiga-Fernandes, a neuroimmunologist at the Champalimaud Centre for the Unknown in Lisbon.
“If we want to use it in the therapeutic context, we actually need to understand the mechanism.“"
Output:
Place: Champalimaud Centre for the Unknown, Lisbon
It's often better to be specific and direct. The more direct, the more effective the message gets across. For example, you might be interested in learning the concept of prompt engineering. You might try something like:
### Instruction ###
Explain the concept prompt engineering.
Keep the explanation short, only a few sentences, and don't be too descriptive.
It's not clear from the prompt above how many sentences to use and what style. You might still somewhat get good responses with the above prompts but the better prompt would be one that is very specific, concise, and to the point. Something like:
Use 2-3 sentences to explain the concept of prompt engineering to a high school student.
Another common tip when designing prompts is to avoid saying what not to do but say what to do instead. This encourages more specificity and focuses on the details that lead to good responses from the model.
2.2 Explain in-context learning.▼
In-context learning is a capability of large language models (LMs) to perform new tasks by conditioning on a few input-label pairs, known as demonstrations, during inference without any gradient updates or model retraining. This approach allows models to generalize to new tasks by observing task examples within the input context, effectively learning through inference alone
Key Concepts of In-Context Learning:
- Demonstrations: The model is presented with examples of input-label pairs (e.g., question-answer pairs) that illustrate the task. These are concatenated in the input prompt along with a test example for which the model generates a prediction.
- Zero-shot vs. Few-shot: In-context learning enhances zero-shot methods, enabling models to perform tasks without prior exposure. However, few-shot learning, which involves presenting the model with a small set of task examples, typically leads to significantly higher accuracy and generalization across diverse tasks by offering context-specific guidance (but requires explicit training/fine-tuning phase).
A fascinating insight from seminal research (Min et al., 2022) challenges our understanding of how language models learn from examples: the accuracy of labels in demonstrations appears to have minimal impact on task performance. Their experiments showed that even when correct labels are randomly replaced with incorrect ones, model performance remains largely unchanged across various classification and multiple-choice tasks. This counter-intuitive finding was consistently observed across different model scales, including GPT-3.
Through extensive experimentation, the researchers uncovered that large language models heavily rely on superficial patterns rather than deep semantic understanding. This suggests that in-context learning functions more as sophisticated pattern matching than true learning - the model uses provided input-output examples to retrieve and apply similar patterns from its training data. However, this mechanism proves fragile: even minor modifications to labeling formats or demonstration templates can significantly degrade performance, revealing the brittle nature of this capability.
2.3 Explain types of prompt engineering.▼
Prompt engineering is the process of crafting and refining prompts to optimize the performance and accuracy of AI language models.
-
Zero-shot Prompting
Description: This involves providing the model with a task or question without giving any examples.
Use Case: When the model is expected to generalize from its pre-existing knowledge.
Example: "Write a summary of the following text."
-
One-shot Prompting
Description: The model is given one example before performing the task.
Use Case: Helps guide the model by offering a single reference point.
Example: "Translate the following sentence into French. Example: 'Hello' -> 'Bonjour'. Now translate: 'Good morning'."
-
Few-shot Prompting
Description: The model receives multiple examples to learn the pattern before completing the task.
Use Case: Useful for complex tasks requiring nuanced understanding.
Example: "Convert these active sentences to passive voice: 'John eats an apple.' -> 'An apple is eaten by John.' 'Sarah writes a book.' -> 'A book is written by Sarah.' Now convert: 'Tom kicks the ball.'"
-
Chain-of-thought Prompting
Description: Encourages the model to explain its reasoning process step by step.
Use Case: Useful for problem-solving and logical reasoning tasks.
Example: "Solve the following math problem by explaining each step. What is 45 divided by 3?"
-
Instruction-based Prompting
Description: The model is explicitly instructed to perform a task in a specific way.
Use Case: Ensures the output follows a strict format or guideline.
Example: "List three benefits of exercise in bullet points."
-
Persona-based Prompting
Description: The model is prompted to respond as if it were a specific character or role.
Use Case: Enhances engagement or aligns the response with a particular tone or expertise.
Example: "You are a nutritionist. Explain the benefits of a balanced diet."
-
Contextual Prompting
Description: The model is provided with relevant context or background information before answering.
Use Case: Helps improve relevance and coherence of responses.
Example: "Given that climate change is accelerating, suggest three ways to reduce carbon emissions."
-
Iterative Prompting
Description: The prompt evolves based on feedback or prior outputs.
Use Case: Improves performance through a refinement loop.
Example: "Rewrite the following paragraph to make it clearer. If necessary, suggest additional edits."
2.4 What are some aspects to keep in mind while using few-shots prompting?▼
Few-shot prompting has emerged as a powerful technique in natural language processing, particularly valuable when labeled data is scarce. This approach, which involves providing a model with carefully selected examples to guide its responses, requires thoughtful consideration of several key elements to maximize its effectiveness. At the foundation of successful few-shot prompting lies the art of example selection and formatting. The examples you choose should represent a diverse range of scenarios within your task's scope while maintaining clarity and unambiguity. It's crucial to establish a consistent format across all examples, clearly delineating inputs from outputs to help the model understand the pattern you want it to follow.
The question of quantity often arises in few-shot prompting. While there's no universal rule, experience shows that three to five examples typically provide a sweet spot between sufficient context and avoiding cognitive overload. This number can be adjusted based on your specific task's complexity and requirements. The arrangement of these examples matters significantly - starting with simpler cases and progressively moving to more complex ones helps the model build understanding gradually, much like how humans learn new concepts.
Task clarity plays a vital role in the success of few-shot prompting. Before presenting any examples, it's essential to establish a clear definition of the task or objective. For complex tasks, explicit instructions can serve as valuable guardrails, helping the model stay on track and deliver more accurate results.
The sensitivity of language models to subtle variations in prompting cannot be overstated. Minor changes in phrasing or example order can significantly impact performance. This characteristic makes it essential to experiment with different approaches and validate outputs regularly. Whether through manual review, automated testing, or cross-validation, consistent output verification helps ensure the model maintains alignment with expected outcomes.
Domain adaptation represents another crucial aspect of effective few-shot prompting. The examples you provide should reflect the specific context and terminology of your target domain. This alignment between examples and domain context significantly enhances the relevance and accuracy of the model's outputs, leading to more practical and applicable results.
2.5 What are certain strategies to write good prompts?▼
Craft effective prompts to elicit clear, relevant, and creative responses. Be specific to avoid vagueness.
- Use "Describe a smartphone for seniors with usability features" instead of "Describe a product."
- Provide context, e.g., "You are a marketing manager launching an energy drink. Write an ad for college students."
- Ask open-ended questions, like "What are the benefits and challenges of remote work?" to encourage detailed answers.
- Guide responses with examples and constraints, such as "Summarize a novel in 100 words with a plot twist."
- Specify tone and style for the audience: "Write a persuasive letter advocating for public transportation expansion."
- Break down complex tasks: "List three waste-reduction strategies and explain their implementation."
- Test and refine prompts by adjusting phrasing. Clarify by adding details, e.g., "Describe a futuristic city in 2050 focusing on technology and sustainability."
2.6 What is hallucination, and how can it be controlled using prompt engineering?▼
Hallucination in AI refers to the generation of incorrect, nonsensical, or fabricated outputs by models, particularly in NLP and generative tasks. These outputs are not grounded in data but appear plausible. This occurs when models misinterpret input or overgeneralize patterns.
Manifestations include: Factual inaccuracies (False information), Logical inconsistencies (Contradictions or errors), and Fabrication (Nonexistent references or data).
Causes of hallucination include incomplete or biased training data, the complexity of models that generate diverse but occasionally erroneous outputs, vague or ambiguous input that prompts fabrication, and overfitting, where models memorize data instead of effectively generalizing.
Prompt engineering refines input to guide AI toward accurate outputs, minimizing hallucinations.
Key Techniques to optimize outputs:
- Precise Language: Use specific prompts. For example, instead of a vague prompt, say, "List NASA space milestones from 1960 to 2020." This helps the model understand exactly what information you are seeking.
- Context: Add relevant background. For instance, if you want a summary of a report, say, "Summarize the 2022 IPCC climate report." Providing context helps the model generate more accurate and relevant information.
- Scope Limitation: Limit the scope of the response. For example, ask, "Give five facts about renewable energy, excluding fossil fuels." This focuses the model's output and avoids unnecessary information.
- Break Down Queries: Enhance clarity by breaking down queries into parts. For example, ask, "Explain the greenhouse effect, then describe CO2's role." This step-by-step approach guides the model through complex topics more effectively.
- Request Sources: Add credibility by requesting sources or citations. For example, say, "List three studies on meditation reducing stress." This encourages the model to provide verifiable information.
Regular monitoring, feedback, and iterative prompt refinement reduce hallucinations. In critical tasks, human oversight ensures accuracy.
2.7 How to improve the reasoning ability of LLM through prompt engineering?▼
Improving the reasoning ability of large language models (LLMs) through prompt engineering involves using specific strategies to guide the model's thought process. Here are some effective techniques:
- Chain-of-Thought Prompting: Enable step-by-step reasoning by explicitly asking the model to break down its thinking process. For example, instead of "What's 13 x 27?", use "Let's solve 13 x 27 step by step. Think through each part of the calculation." Chain-of-thought (CoT) prompting, as originally outlined by Wei et. al. in their paper "Chain of Thought Prompting Elicits Reasoning in Large Language Models", is a form of few-shot prompting. Few-shot prompting, in contrast to zero-shot prompting, involves providing an “exemplar” (example) of a similar question and answer pair before posing the question which the LLM should solve. In CoT prompting, the exemplar answer walks through the problem step-by-step. This compels the LLM to then respond to the real question step-by-step, mimicking the exemplar answer.
- Zero-Shot Chain-of-Thought: Zero-shot chain-of-thought prompting, as outlined by Kojima et. al. in their paper "Large Language Models are Zero-Shot Reasoners", attempts to emulate this effect by simply appending the phrase “let’s think step by step” to the prompt, without providing an exemplar. It is crucial to understand that this zero-shot chain-of-thought prompting is the form of CoT prompting which this novel method seeks to improve, not the original “few-shot” CoT prompting.
- LoT Prompting (Logic of Thought Prompting): LoT prompting begins by asking the LLM to solve the problem step by step, similar to zero-shot chain-of-thought prompting. After the LLM provides its initial step-by-step solution, follow-up prompts instruct it to verify each step. Specifically, the LLM is asked to give both a positive and negative review for each step, then justify the correct part of the reasoning and criticize the incorrect one, based on the original problem’s premises. If necessary, the LLM is directed to revise the step according to its own critique. Once a step is revised or confirmed, the original problem is restated, along with the verified or updated steps, to ensure the solution is coherent and accurate.
- Self-Consistency: Ask the model to approach the problem from multiple angles and cross-check its reasoning. For instance, "Solve this problem using two different methods and verify that they give the same result."
-
Program of Thoughts (PoT):
Program of Thoughts (PoT) is a prompting technique that combines the
strengths of Chain-of-Thought (CoT) and program synthesis. It
involves generating a program or a sequence of instructions that the
model can follow to solve a problem. This approach leverages the
model's ability to understand and execute structured instructions,
leading to more accurate and reliable reasoning. In PoT, the large
language models (LLMs) are primarily responsible for expressing the
‘reasoning process’ in a programming language, while the computation
is delegated to an external process, such as a Python interpreter.
By disentangling computation from reasoning, PoT addresses
challenges LLMs face in generating complex equations, such as those
involving cubes or polynomials. Key aspects of PoT include:
- Breaking down problems into a multi-step ‘thought’ process.
-
Binding semantic meanings to variables. By using semantically
meaningful variable names (e.g.,
interest_rateorsum_in_two_years_with_interest), PoT creates a structured representation that aligns with human reasoning.
PoT Evaluation:
- PoT has been tested across multiple datasets, including mathematical word problems (MWP) and financial datasets.
- In few-shot settings, PoT showed an average gain of 8% over CoT on MWP datasets and 15% on financial datasets. In zero-shot settings, it achieved a 12% average gain on MWP datasets.
- Combining PoT with self-consistency (SC) decoding further improved performance, outperforming CoT+SC by an average of 10%.
- PoT+SC achieved the best-known results on MWP datasets and near-best results on financial datasets (excluding GPT-4).
The following diagram illustrates how PoT resolves complex problems that traditional CoT approaches fail to address, utilizing Python programs to express reasoning and relying on a Python interpreter for computation.

Source: arxiv.org/2211.12588
- Structure Decomposition: Break complex problems into smaller sub-problems. For example, instead of "Analyze this investment strategy," use "Let's analyze this investment strategy by first examining the risk factors, then calculating potential returns, and finally evaluating market conditions."
- Explicit Constraints and Requirements: Clearly state what constitutes valid reasoning. For example, "Your solution must include clear assumptions, mathematical justification, and potential edge cases."
- Role Prompting: Assign a specific expert role to encourage domain-specific reasoning. For example, "As a mathematical logician, explain why..."
- Meta-Cognition Prompting: Ask the model to evaluate its own reasoning. For example, "After providing your solution, explain which parts of your reasoning you're most and least confident about."
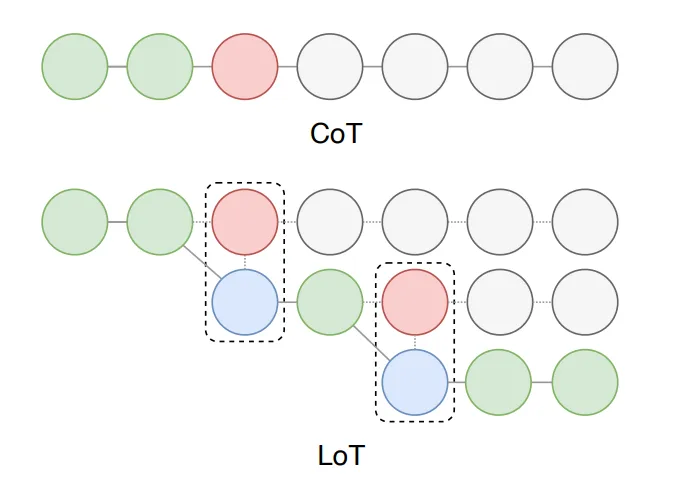
2.8 How to improve LLM reasoning if your COT prompt fails?▼
CoT prompts help guide logical steps, but their effectiveness depends heavily on their design and context.
Clarity in the prompt is crucial. Specific instructions tailored to the problem often yield better results than vague requests. Breaking problems into smaller parts makes reasoning more manageable, particularly when combined with illustrative examples. For instance, guiding the model to identify known quantities, apply formulas, and simplify step-by-step enhances accuracy. Context is another key factor. Prompts lacking sufficient information can confuse the model. Including necessary background or providing structured inputs such as diagrams or tables helps clarify expectations. Rephrasing questions or representing problems visually can also aid reasoning. Experimenting with different phrasings often reveals what works best for the model. Self-verification is a valuable technique. Prompts that ask the model to review and justify its solutions can uncover errors and fill gaps in logic. Integrating external tools can further support structured reasoning. For example, pairing the LLM with symbolic solvers or computation platforms like WolframAlpha ensures precision in tasks requiring formal logic or accurate calculations.
3. Retrieval Augmented Generation (RAG)
3.1 How to increase accuracy, reliability, and make answers verifiable in LLM?▼
Before diving into specific improvements, it's essential to understand that LLM accuracy and reliability stem from three core components: the model's architecture, its training process, and its deployment framework.
Data Quality Optimization
The cornerstone of any reliable LLM lies in its training data. High-quality data requires both breadth and depth, starting with comprehensive data selection. Breadth ensures representation of diverse perspectives and writing styles, such as technical manuals, academic papers, and creative works, while depth focuses on in-depth exploration within specific knowledge domains for richer context. This includes materials ranging from academic publications and peer-reviewed research to technical documentation and professional guides, all carefully vetted for accuracy and relevance.
Raw data must undergo careful cleaning and preprocessing to ensure its utility. This process begins with deduplication to prevent overrepresentation of certain viewpoints, followed by content filtering to remove problematic or incorrect information. The data then undergoes standardization of formatting and structure, enrichment with metadata for better context understanding, and implementation of version control for tracking provenance.
Enhanced Training Methodologies
Modern LLM training demands sophisticated approaches that go beyond basic supervised learning. Constitutional AI training helps instill reliable behavior patterns, while multi-task learning improves the model's ability to generalize across different domains. Curriculum learning introduces concepts progressively, moving from simple to complex topics in a structured manner that mirrors human learning patterns. For example, training could begin with foundational grammar and syntax exercises, proceed to intermediate text comprehension tasks, and culminate in advanced applications such as contextual reasoning or creative content generation.
Fine-tuning represents another critical aspect of training. This process requires careful attention to task-specific data collection and curation, coupled with meticulous hyperparameter optimization.
Knowledge Integration Systems
Retrieval-Augmented Generation (RAG) serves for enhancing LLM accuracy by combining a language model with external knowledge retrieval. Unlike traditional methods that rely solely on static training data, RAG dynamically fetches relevant information from up-to-date knowledge bases during the generation process, improving the timeliness and relevance of outputs. This system provides real-time access to verified knowledge bases, enabling dynamic fact-checking during generation. Knowledge graph integration further improves reliability by providing structured representation of information. This approach enables explicit modeling of relationships between concepts, creating a hierarchical organization that facilitates cross-reference verification and logical consistency checking.
Verification and Control Systems
A robust verification framework implements multi-stage verification pipelines, such as source-based validation workflows or AI-enhanced fact-checking mechanisms, that perform fact-checking against trusted sources while maintaining consistency across responses. Uncertainty quantification helps identify areas where the model might be less confident, while source attribution tracking ensures transparency in the model's decision-making process.
By carefully managing temperature and sampling parameters, these systems help ensure consistent output quality. They also enforce topic boundaries and confidence thresholds, preventing the model from generating responses in areas where it lacks sufficient knowledge or confidence.
Monitoring and Maintenance
Automated accuracy assessments can run regularly to identify and log discrepancies in performance, while user feedback analysis systems track and prioritize common concerns or suggestions. Regular maintenance includes scheduled knowledge base updates, model retraining sessions, and fine-tuning refinement. System optimization occurs continuously, informed by performance metrics and user feedback.
Expert Collaboration Framework
Maintaining high accuracy and reliability necessitates ongoing human oversight. This involves streamlined workflows for expert review and feedback, ensuring human expertise guides training data validation, output quality assessment, and the overall model development process.
3.2 How does RAG work?▼
Think of RAG as a smart assistant with both a powerful memory (retrieval) and the ability to generate thoughtful responses (generation). Just like how you might look up references before writing an essay, RAG enhances language model outputs by first consulting relevant information from a knowledge base.
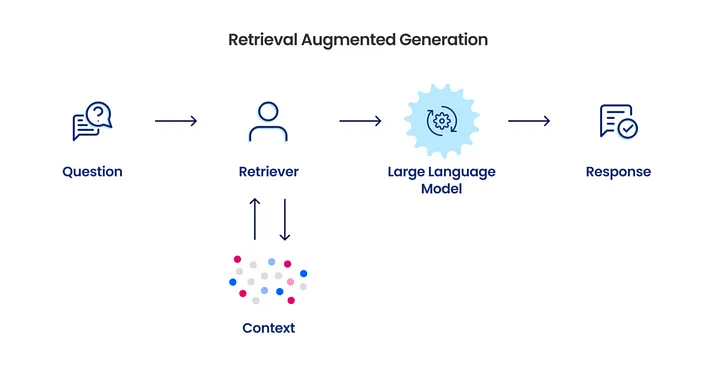
Upon receiving a user query, RAG employs parsing techniques to dissect the input into salient components optimized for retrieval. For instance, a query like, "What are the health benefits of green tea?" would be parsed to emphasize terms such as "health benefits" and "green tea," which then serve as anchors for the subsequent retrieval process.
The retrieval subsystem uses vectorized representations, commonly referred to as embeddings, which are computed using neural models (e.g., SentenceTransformers). These embeddings encapsulate semantic relationships within the dataset, enabling the efficient identification of highly relevant information. The retrieval phase systematically measures the semantic proximity between the query embedding and pre-encoded document embeddings, returning a curated subset of information most pertinent to the query.
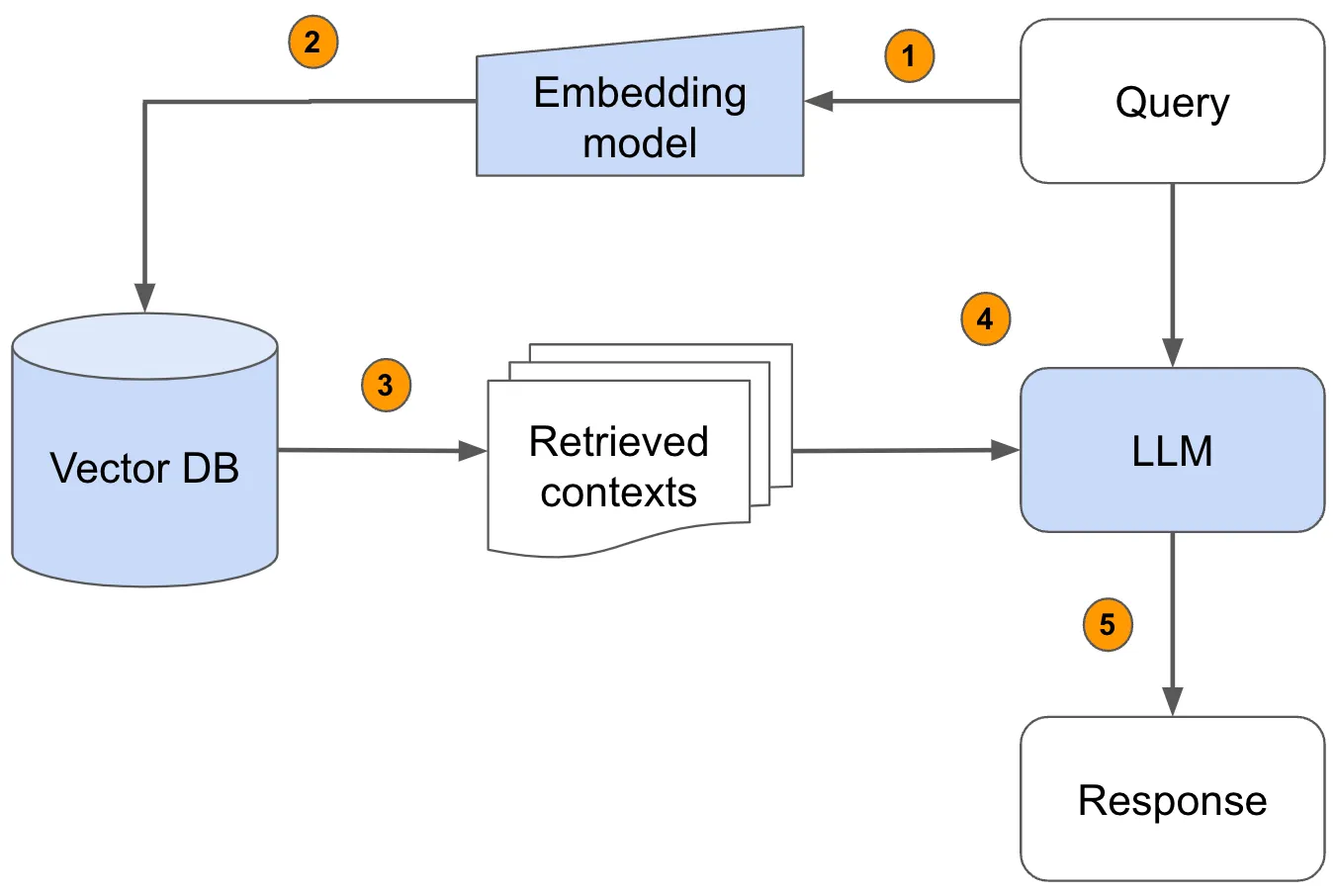
In the generative phase, the model synthesizes the retrieved context with the original query. Unlike standalone generative models that rely exclusively on pre-existing training corpora, RAG dynamically incorporates retrieved information, significantly mitigating the risk of hallucination.
A defining feature of RAG is its modular retrieval system, enabling dynamic updates to the knowledge repository without necessitating exhaustive retraining of the underlying generative model. This modularity ensures scalability and adaptability, rendering RAG highly suitable for domains characterized by rapid knowledge evolution.
To elucidate the mechanics of RAG, consider the following Python-based implementation:
# First, we create embeddings for our knowledge base
from sentence_transformers import SentenceTransformer
from vectorstore import VectorStore # Hypothetical vector store
# Initialize the embedding model
embedder = SentenceTransformer('all-mpnet-base-v2')
# Create embeddings for our documents
documents = ["Green tea contains antioxidants...", "Studies show green tea may..."]
document_embeddings = embedder.encode(documents)
# Store embeddings in vector database
vector_store = VectorStore()
vector_store.add(document_embeddings, documents)
# When a query comes in:
def rag_response(query, llm):
# 1. Create embedding for the query
query_embedding = embedder.encode(query)
# 2. Retrieve relevant documents
relevant_docs = vector_store.similarity_search(query_embedding, k=3)
# 3. Combine query and retrieved docs into prompt
context = "\n".join(relevant_docs)
prompt = f"Context: {context}\nQuestion: {query}\nAnswer:"
# 4. Generate response using language model
response = llm.generate(prompt)
return response
This code snippet illustrates a simplified RAG implementation. The system first creates embeddings for the knowledge base documents, retrieves relevant information based on the user query, and then generates a response by combining the query with the retrieved context.
The real power of RAG comes from its ability to combine the broad capabilities of large language models with specific, retrievable knowledge.
Image sources: What is Retrieval-Augmented Generation (RAG) in LLM and How It Works?
3.3 What are some benefits of using the RAG system?▼
Retrieval-Augmented Generation (RAG) systems mitigate the propensity for hallucination by anchoring generated responses in specific, retrievable source documents. This mechanism ensures output reliability and diminishes the dissemination of inaccuracies.
Here some key benefits of employing RAG systems:
- Cost-Effective Knowledge Updates: The modular architecture of RAG systems permits seamless integration of updated knowledge without necessitating comprehensive model retraining. This paradigm presents a cost-efficient alternative to traditional fine-tuning, particularly salient for contexts necessitating frequent updates.
- Improved Transparency and Auditability: RAG systems can trace their responses back to specific source documents, making the decision-making process more transparent. Organizations can verify the sources of information and maintain clear documentation of how responses are generated.
- Customization Without Complex Training: Organizations can tailor the system's knowledge to their specific domain by curating the retrieval database. Companies can incorporate proprietary information, internal documentation, and industry-specific knowledge while maintaining the base model's general capabilities.
- Lower Computational Requirements: Compared to expanding the size of language models to incorporate more knowledge, RAG systems often require less computational power to operate effectively. This results in lower infrastructure costs and faster response times.
- Enhanced Privacy and Control: Organizations maintain greater control over sensitive information by managing their own retrieval database. This allows them to implement proper data governance and ensure compliance with privacy regulations while still leveraging the capabilities of large language models.
3.4 When should I use Fine-tuning instead of RAG?▼
Fine-tuning is recommended when it is necessary to modify the model's core behavior—such as its ability to prioritize certain types of tasks, interpret input data differently, or refine output generation—or adapt its style to specific requirements.
Moreover, fine-tuning is valuable for integrating niche terminologies or domain-specific knowledge deeply into the model’s understanding, such as by adjusting embeddings to prioritize relevant terms or modifying loss functions to enhance performance on specialized datasets.
When to Prefer RAG
RAG is generally the better choice if the primary goal is to incorporate up-to-date factual information or align the model with evolving knowledge. This approach is useful when referencing specific documents, ensuring accuracy for dynamic data, or providing responses supported by citations.
Cost and Resource Considerations
The choice between these approaches often depends on practical considerations, including scalability and maintainability. Fine-tuning might be less scalable due to the need for repeated retraining as new data becomes available, whereas RAG systems can adapt more flexibly by updating the knowledge base. Additionally, maintainability can be a challenge for fine-tuning, as it often requires ongoing supervision to ensure relevance, while RAG generally simplifies long-term upkeep. Fine-tuning requires significant computational resources. Additionally, it requires a substantial and high-quality dataset for optimal results. In contrast, RAG can be updated by simply modifying the underlying knowledge base, making it more cost-effective and easier to maintain for many applications.
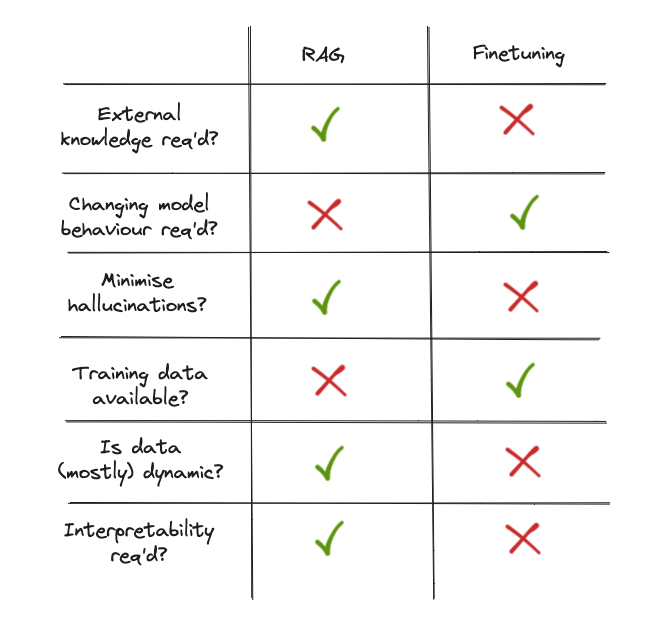
In some cases, combining both approaches may provide the best solution. For example, a hybrid customer support system could use fine-tuning to maintain a consistent and professional tone in interactions, while leveraging RAG to provide accurate and current responses by retrieving the latest product or policy information from an external database. In this case, it will be necessary to maintain both systems. Taking everything into account, RAG is generally the preferred choice in most scenarios.
3.5 What are the architecture patterns for customizing LLM with proprietary data?▼
Retrieval-Augmented Generation (RAG) integrates external data retrieval into the generation process of Large Language Models (LLMs), enhancing their ability to provide accurate and contextually relevant responses. When customizing LLMs with proprietary data, several RAG architecture patterns can be employed:
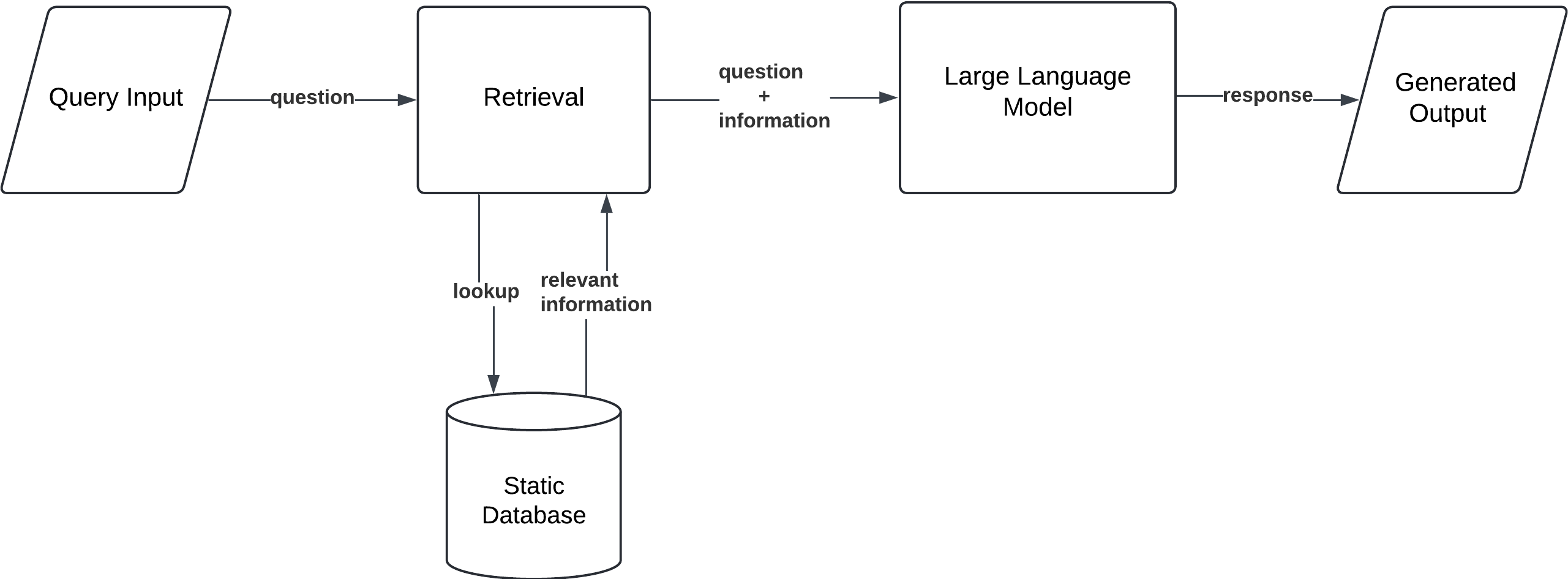
Simple RAG
In this basic configuration, the model retrieves relevant documents from a static proprietary database in response to a query and generates an output based on the retrieved information.
Workflow:
- Query Input: The user provides a prompt or question.
- Document Retrieval: The model searches a fixed database to find relevant information.
- Generation: Based on the retrieved documents, the model generates a response grounded in real-world data.
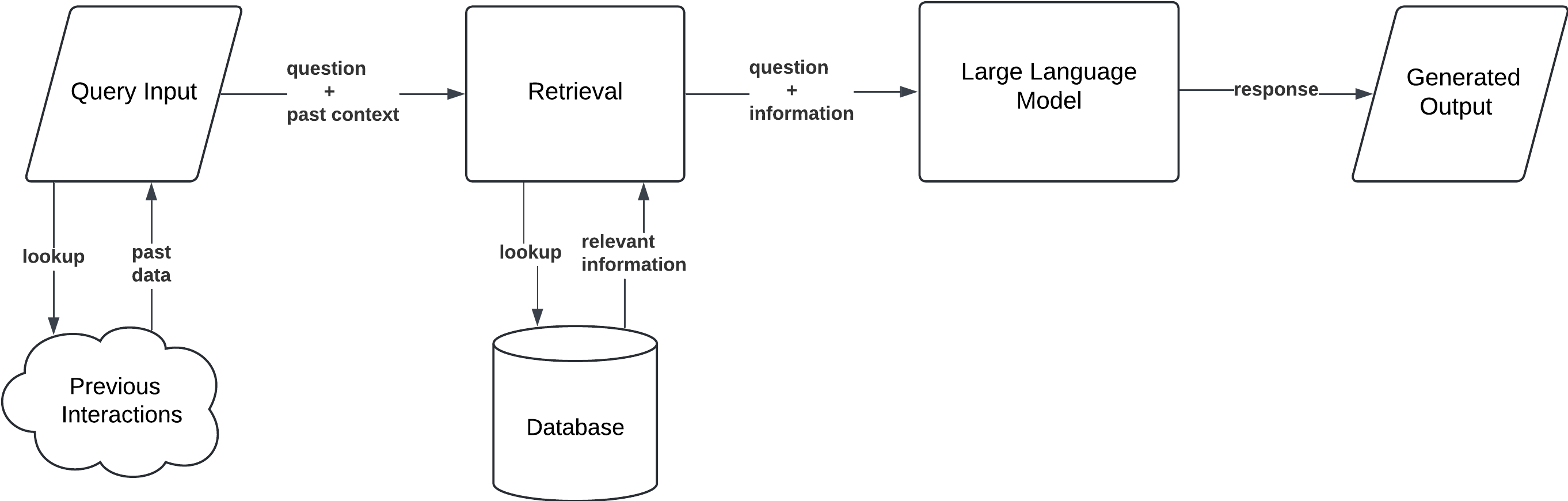
Simple RAG with Memory
This configuration includes a memory component, allowing the model to retain and utilize information from previous interactions. It is particularly useful for continuous conversations or tasks requiring contextual awareness across multiple queries.
Workflow:
- Query Input: The user submits a query or prompt.
- Memory Access: The model retrieves past interactions or data stored in its memory.
- Document Retrieval: It searches the external database for new relevant information.
- Generation: The model generates a response by combining retrieved documents with stored memory.
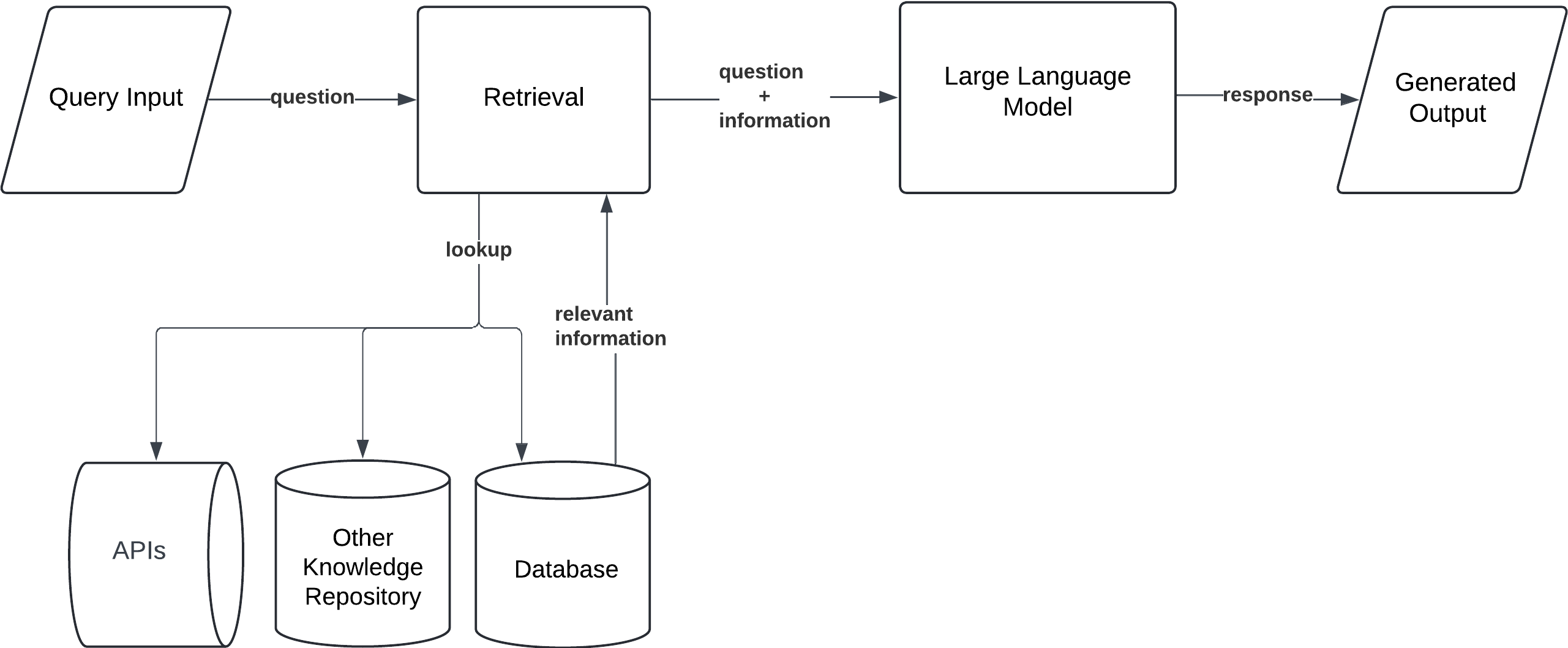
Branched RAG
This pattern enables the model to dynamically select specific data sources based on the input query, retrieving information from the most relevant proprietary databases. It’s ideal for complex queries that require specialized knowledge from distinct domains.
Workflow:
- Query Input: The user submits a prompt.
- Branch Selection: The model evaluates multiple retrieval sources and selects the most relevant one based on the query.
- Single Retrieval: The model retrieves documents from the selected source.
- Generation: The model generates a response based on the retrieved information from the chosen source.
HyDe (Hypothetical Document Embedding)
In this approach, the model generates a hypothetical document based on the query, embeds it, and retrieves actual documents similar to this embedding from the proprietary data. This method enhances retrieval effectiveness, especially when direct matches are scarce.
Workflow:
- Query Input: The user provides a prompt or question.
- Hypothetical Document Creation: The model generates an embedded representation of an ideal response.
- Document Retrieval: Using the hypothetical document, the model retrieves actual documents from a knowledge base.
- Generation: The model generates an output based on the retrieved documents, influenced by the hypothetical document.
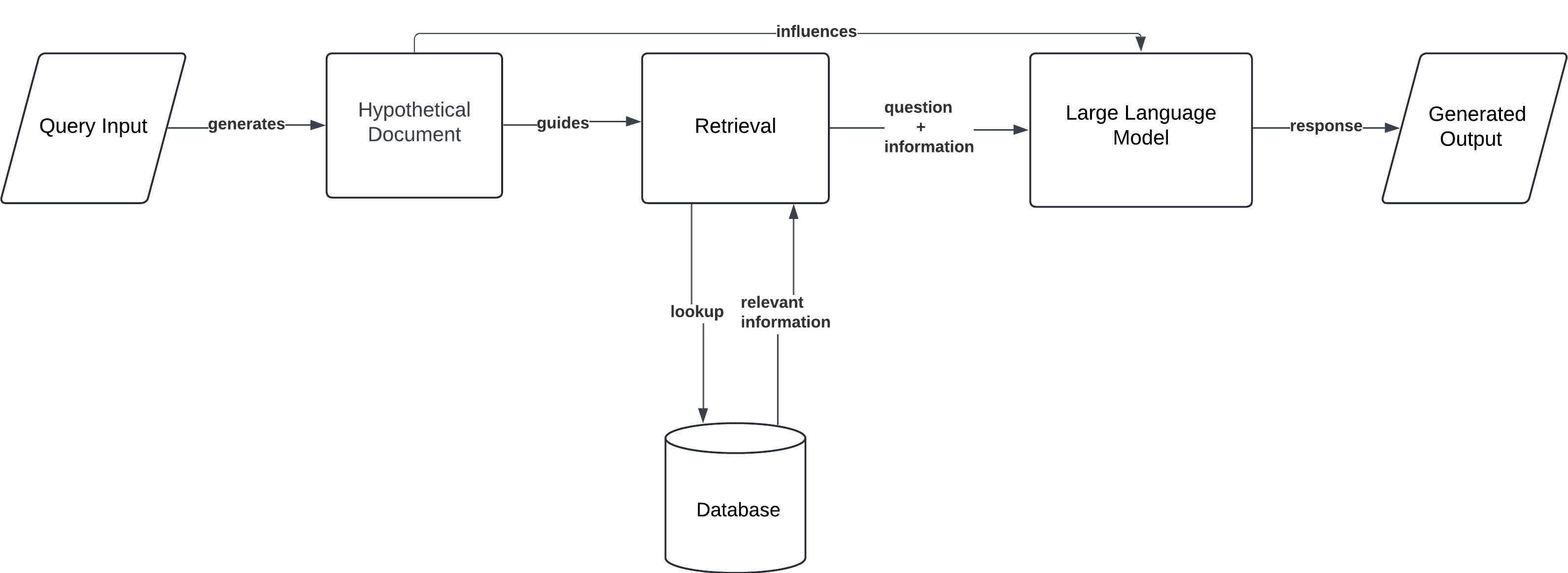
HyDe is especially useful for research and development, where queries may be vague, and retrieving data based on ideal or hypothetical responses helps refine complex answers. It also applies to creative content generation when more flexible, imaginative outputs are needed.
Adaptive RAG
Adaptive RAG dynamically adjusts its retrieval strategy based on the complexity or nature of the query. For simple queries, it might retrieve documents from a single source, while for more complex queries, it may access multiple data sources or employ sophisticated retrieval techniques.
Workflow:
- Query Input: The user submits a prompt.
- Adaptive Retrieval: Based on the query's complexity, the model decides whether to retrieve documents from one or multiple sources, or to adjust the retrieval method.
- Generation: The model processes the retrieved information and generates a tailored response, optimizing the retrieval process for each specific query.
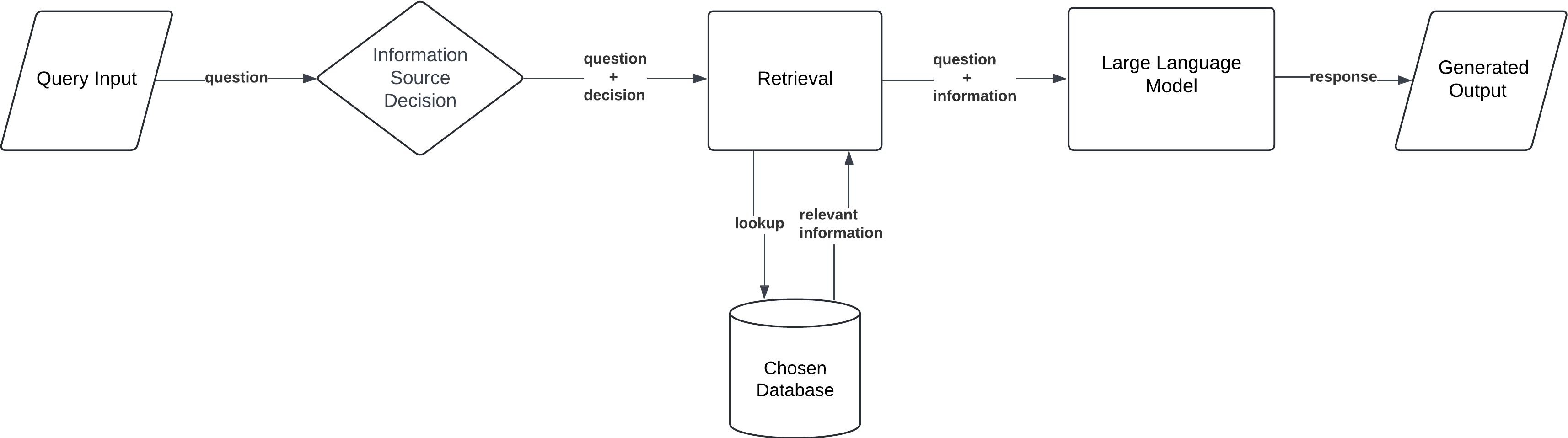
Adaptive RAG is useful for enterprise search systems, where the nature of the queries can vary significantly. It ensures both simple and complex queries are handled efficiently, providing the best balance of speed and depth.
Corrective RAG (CRAG)
This pattern introduces a self-reflection mechanism, evaluating retrieved documents to improve response accuracy. For instance, a retrieved document might be split into "knowledge strips" such as key paragraphs or sentences. Each strip is then scored for relevance on a scale (e.g., 1 to 5), with highly relevant strips prioritized for response generation.
Workflow:
- Query Input: The user submits a query or prompt.
- Document Retrieval: The model retrieves documents from the knowledge base and evaluates their relevance.
- Knowledge Stripping and Grading: The retrieved documents are broken down into "knowledge strips" — smaller sections of information. Each strip is graded based on relevance.
- Knowledge Refinement: Irrelevant strips are filtered out. If no strip meets the relevance threshold, the model seeks additional information.
- Generation: Once a satisfactory set of knowledge strips is obtained, the model generates a final response based on the most relevant and accurate information.
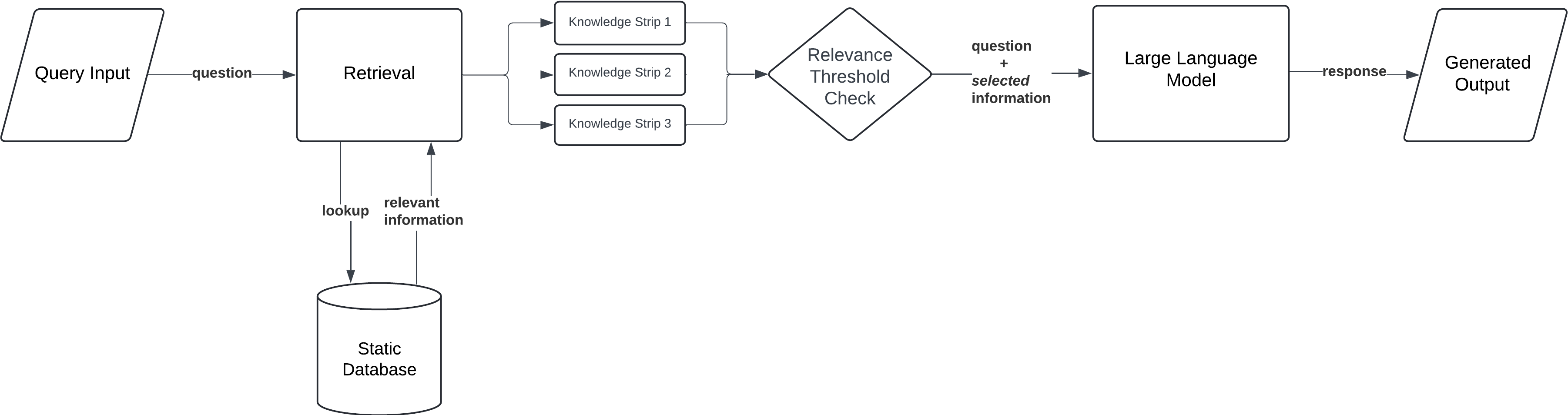
Corrective RAG is ideal for applications requiring high factual accuracy, where even minor inaccuracies can lead to significant consequences.
Self-RAG
Self-RAG autonomously generates retrieval queries during the generation process. For example, in an exploratory research scenario, a researcher might ask about "recent trends in renewable energy storage." Initially, the model retrieves documents on general energy storage. As gaps are identified—such as a lack of information on specific materials or recent breakthroughs—the model generates targeted queries like "advances in lithium-sulfur batteries" or "policy impacts on renewable storage in 2023," iteratively refining the response with more precise and relevant details.
Workflow:
- Query Input: The user submits a prompt.
- Initial Retrieval: The model retrieves documents based on the user’s query.
- Self-Retrieval Loop: During the generation process, the model identifies gaps in the information and issues new retrieval queries to find additional data.
- Generation: The model generates a final response, iteratively improving it by retrieving further documents as needed.
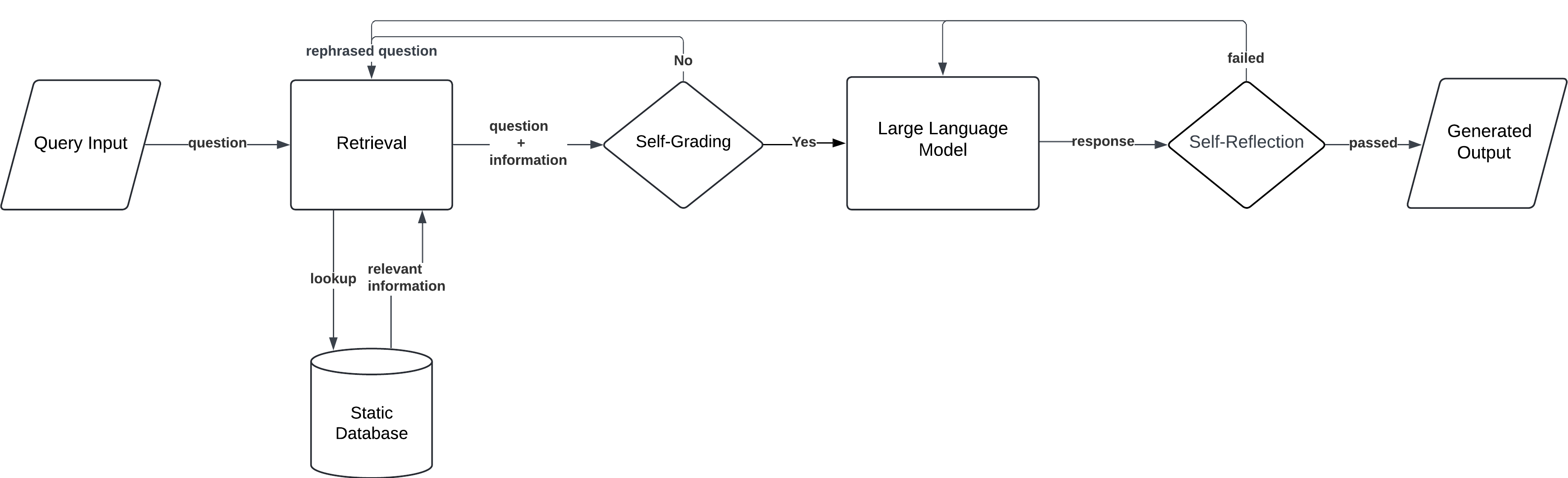
Self-RAG is highly effective in exploratory research or long-form content creation, where the model needs to pull in more information dynamically as the response evolves.
Agentic RAG
This implementation provides agent-like behavior, where the model proactively interacts with multiple data sources or APIs to gather information. It uses a Meta-Agent to manage interactions between individual Document Agents, enabling sophisticated decision-making for complex tasks.
Workflow:
- Query Input: The user submits a complex query or task.
- Agent Activation: The model activates multiple agents. Each Document Agent is responsible for a specific document.
- Multi-step Retrieval: The Meta-Agent manages and coordinates the interactions between the various Document Agents.
- Synthesis and Generation: The Meta-Agent integrates the outputs from the individual Document Agents and generates a comprehensive response.
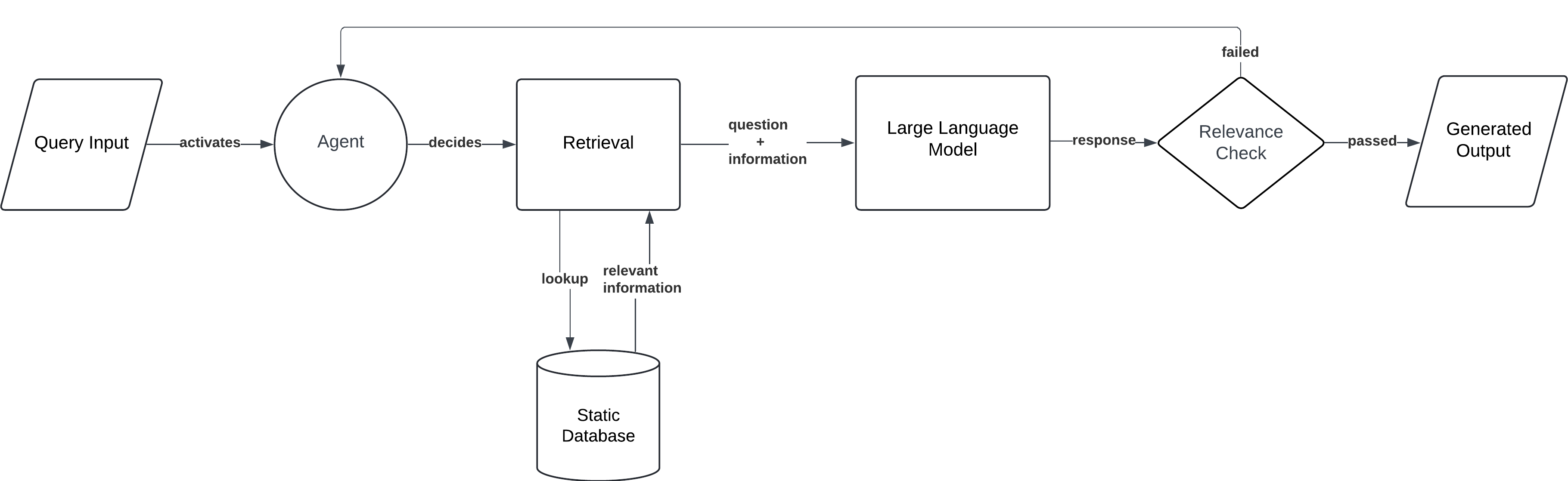
Agentic RAG is perfect for tasks like automated research, multi-source data aggregation, or executive decision support, where the model needs to autonomously pull together and synthesise information from various systems.
Graph RAG
A baseline RAG usually integrates a vector database and an LLM, where the vector database stores and retrieves contextual information for user queries, and the LLM generates answers based on the retrieved context. While this approach works well in many cases, it struggles with complex tasks like multi-hop reasoning or answering questions that require connecting disparate pieces of information.
For example, consider this question: “What name was given to the son of the man who defeated the usurper Allectus?”
- Identify the Man: Determine who defeated Allectus.
- Research the Man’s Son: Look up information about this person’s family, specifically his son.
- Find the Name: Identify the name of the son.
The challenge usually arises at the first step because a baseline RAG retrieves text based on semantic similarity, not directly answering complex queries where specific details may not be explicitly mentioned in the dataset. To address such challenges, Microsoft Research introduced GraphRAG, a brand-new method that augments RAG retrieval and generation with knowledge graphs.
Graph RAG incorporates graph-based data structures into the retrieval process, allowing the model to retrieve and organize information based on entity relationships. This approach is particularly useful in contexts where the data structure is crucial for understanding, such as knowledge graphs, social networks, or semantic web applications.
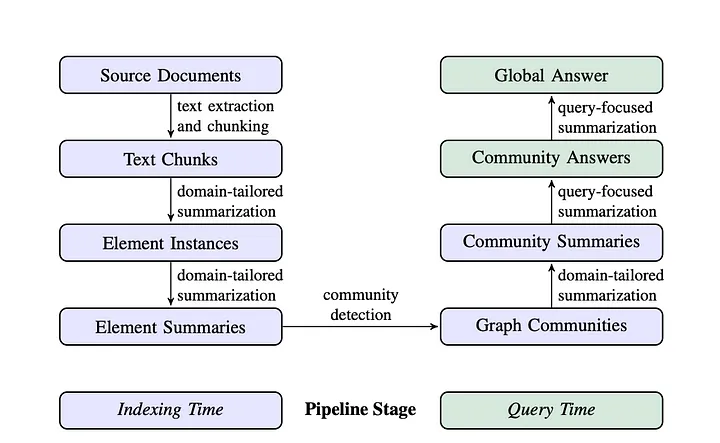
Workflow:
- Query Input: The user submits a query.
- Graph Navigation: The model traverses the graph to retrieve both isolated information and the relationships between entities.
- Generation: The model synthesizes a response that reflects both the retrieved data and its relational context.
Graph RAG excels in domains requiring deep relational understanding. Ensuring that graph structures are updated and maintained accurately, as outdated or incomplete graphs could lead to incorrect or incomplete responses.
Sources:
RAG Architectures - Humanloop Blog,
From Local to Global: A Graph RAG Approach to Query-Focused
Summarization
4. Fine-tuning of LLMs
4.1 What is fine-tuning, and why is it needed?▼
Fine-tuning, in the context of machine learning, refers to the process of adapting a pre-trained model to perform specific tasks or meet particular needs. This technique, which falls under the domain of transfer learning, is a fundamental tool for training foundational models used in generative AI and other deep learning applications.
Training a machine learning model from scratch can be extremely resource-intensive and time-consuming, especially for models with millions or billions of parameters. Fine-tuning addresses this challenge by using the knowledge already acquired by a pre-trained model. Starting from a model with a general knowledge base, the adaptation process requires significantly less computational power and fewer labeled data compared to training a new model entirely from scratch.
Although fine-tuning is part of the broader training process, it is distinct from what is traditionally referred to as "training." For clarity, the initial training phase of a model is commonly termed pre-training. At the beginning of pre-training, a model starts with randomly initialized parameters, including weights and biases. The training process iteratively adjusts these parameters in two phases: Forward Pass and Backpropagation. In contrast, LLMs typically employ self-supervised learning (SSL) for pre-training. SSL uses unlabeled data and pretext tasks designed to derive ground truth from the data's inherent structure.
Fine-tuning is versatile and applicable across many fields:
- Natural Language Processing (NLP): Adjusting the conversational tone or enhancing the domain-specific knowledge of LLMs.
- Computer Vision: Adapting pre-trained convolutional neural networks (CNNs) or Vision Transformers (ViTs) for tasks such as image segmentation, object detection, or domain-specific classification.
- Generative Models: Modifying the style or content-generation capabilities of pre-trained models to meet specific requirements.
- Specialized Domains: Incorporating proprietary or domain-specific datasets into models.
4.2 Which scenario do we need to fine-tune LLM?▼
Fine-tuning is necessary in the following scenarios to adapt large language models (LLMs) to specific requirements or use cases:
1. Tone, Style, and Format Customization
Fine-tuning is beneficial for tailoring an LLM to adhere to a particular persona, tone, or style that resonates with a specific audience. It is also helpful for structuring output in a preferred format like JSON, YAML, or Markdown. Custom datasets enable the LLM to generate responses that closely align with the intended user experience or expectations.
2. Increasing Accuracy and Handling Edge Cases
LLMs may struggle with certain challenges, such as hallucinations, subtle errors, or complex instructions that are not adequately addressed by prompt engineering or in-context learning. Fine-tuning can significantly improve accuracy in specific tasks, such as sentiment analysis, by leveraging a relatively small set of examples:
- For example, Phi-2's accuracy on financial data sentiment analysis increased from 34% to 85%.
- ChatGPT's Reddit comment sentiment analysis accuracy improved from 48% to 73% with just 100 examples. Fine-tuning is particularly effective for cases where baseline accuracy is under 50%, often yielding significant improvements with only a few hundred data samples.
3. Addressing Underrepresented Domains
LLMs are often trained on general data and might lack proficiency in specific or niche domains such as medical, legal, or financial sectors. Fine-tuning helps models to:
- Adapt to domain-specific jargon and terminology.
- Perform tasks like summarizing sensitive medical histories or handling data in underrepresented languages.
- Example: Fine-tuning with Parameter Efficient Fine-Tuning (PEFT) techniques improved performance across all tasks in Indic languages.
4. Cost Reduction
Fine-tuning can optimize a smaller model by transferring knowledge from a larger model, like GPT-4 distilled into GPT-3.5 or Llama 2 70B compressed into Llama 2 7B. This process reduces computational costs and latency while maintaining high quality. Fine-tuning also minimizes the need for detailed prompt engineering, leading to token savings and reduced operating costs.
5. Enabling New Tasks or Abilities
Fine-tuning can enable capabilities beyond the pretrained functionality of an LLM. For example:
- Utilizing or ignoring the context retrieved by external systems.
- Enhancing evaluation metrics such as compliance, helpfulness, or groundedness when fine-tuned as an LLM judge.
- Extending the model's context window to handle larger inputs efficiently.
Comparison with In-Context Learning (ICL) and Retrieval-Augmented Generation (RAG)
In-context learning is a simpler alternative that involves providing examples within the prompt to guide the LLM's response. While effective, it has limitations:
- As the number of examples increases, inference cost and latency grow.
- With too many examples, LLMs may ignore some, necessitating systems like RAG to retrieve the most relevant examples.
- LLMs may reproduce the knowledge from examples verbatim, a concern shared with fine-tuning. ICL serves as a valuable preliminary approach to assess whether fine-tuning could enhance performance on downstream tasks.
RAG systems incorporate external knowledge retrieval to supplement LLMs, making them suitable for dynamic data or knowledge-intensive tasks. Key considerations include:
- External Knowledge: RAG excels in injecting external information dynamically, whereas fine-tuning embeds static knowledge.
- Custom Requirements: Fine-tuning is ideal for aligning tone, behavior, or vocabulary.
- Hallucination Mitigation: RAG provides built-in mechanisms to reduce hallucinations, making it preferable in applications requiring high factual accuracy.
- Adaptability: Fine-tuning struggles with rapidly changing data, while RAG leverages live data sources.
- Interpretability: RAG inherently offers transparency with references, aiding in interpretability.
- Cost and Expertise: Building RAG systems may demand expertise in search systems, while fine-tuning necessitates robust data gathering and improvement strategies.
Often, combining fine-tuning and RAG yields the best results. Fine-tuning customizes the model's behavior, while RAG supplements it with dynamic, up-to-date knowledge. Cost, complexity, and additional benefits should guide the decision to adopt either or both approaches, with experimentation and error analysis providing critical insights for optimization.
Source: https://ai.meta.com/blog/when-to-fine-tune-llms-vs-other-techniques/
4.3 How to decide if fine-tuning is necessary?▼
Fine-tuning adapts LLMs to specific tasks or domains, often yielding significant performance gains. However, it's not always necessary or beneficial. Understanding when fine-tuning is required is critical for optimizing project success and resource allocation. Here's how to approach the decision:
Task Suitability
Fine-tuning is most effective for tasks requiring specialized domain knowledge. It also helps tailor models for highly specific tasks like structured data extraction, content moderation, or generating consistent brand-aligned content.
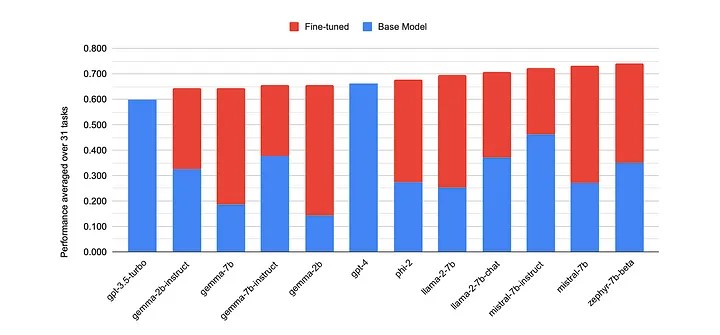
General-purpose models like GPT-4 and Llama 3 offer strong baseline performance. However, they can fall short for domain-specific tasks (e.g., clinical note analysis), specialized skills (e.g., advanced mathematics), or language-specific nuances (e.g., low-resource dialects).
Data Considerations
High-quality, task-specific data is essential for effective fine-tuning. For continual pre-training, terabytes of text data may be required, especially when introducing new domain-specific knowledge. Supervised fine-tuning typically needs fewer examples, ranging from hundreds for simple tasks to thousands for complex ones. Regardless of the approach, ensure data relevance, cleanliness, and proper licensing, and address privacy concerns where applicable.
Resource and Expertise Requirements
Fine-tuning can be resource-intensive, necessitating:
- Hardware: High-performance GPUs or TPUs.
- Financial investment: Costs for hosting a fine-tuned model may outweigh the benefits for low-volume applications.
- Expertise: Domain knowledge for prompt crafting, machine learning for evaluation metrics, and engineering for inference optimization in real-time applications.
Recent innovations in fine-tuning techniques have made working with large models more accessible. A key example is QLoRA (Quantized Low-Rank Adaptation), which significantly reduces memory requirements compared to traditional fine-tuning approaches. To illustrate this, consider the peak GPU memory usage when fine-tuning Llama 2 7B using different methods:
| Fine-tuning Method | Peak GPU Memory (GB) |
|---|---|
| Full fine-tuning | 24.1 |
| LoRA | 21.3 |
| QLoRA | 12.3 |
Note: QLoRA achieves these results using 4-bit NormalFloat quantization.
Task Complexity and Specificity
Fine-tuning offers the most value for tasks with narrow, well-defined scopes. For example, sentiment analysis for a specific product category benefits more from fine-tuning than general text classification. Metrics like input/output lengths, data compressibility, and content diversity can help assess task complexity.
Highly specific formats, such as JSON extraction or summarization for particular document types, also often benefit from fine-tuning.
Maintenance and Operational Complexity
Fine-tuned models require ongoing updates and version management, adding operational complexity. While ideal for stable, high-volume tasks, this approach may not suit rapidly evolving requirements or prototypes.
Before fine-tuning, consider these simpler and less costly alternatives:
- Prompt engineering: Optimize prompts to leverage existing model capabilities without modifying weights.
- Feature extraction: Use pre-trained models as feature extractors, adding lightweight task-specific layers.
- Few-shot learning: Leverage in-context learning with a small number of examples.
- Small-scale testing: Pilot fine-tuning on a subset of data to evaluate performance gains and justify the added complexity and cost compared to baseline models.
4.4 How do you improve the model to answer only if there is sufficient context for doing so?▼
When enhancing a language model's ability to respond based on context sufficiency, we should focus on four key areas to ensure reliable and accurate responses.
Contextual Assessment Framework
Implementation of a robust system that evaluates context completeness before generating responses is essential. This involves developing sophisticated keyword matching algorithms, applying semantic analysis through topic modeling, and establishing minimum context length requirements. The system should utilize sentence embeddings to comprehend the overall topic relevance and ensure all necessary information is present for generating accurate responses.
Response Generation Controls
The development of a controlled response mechanism requires two primary methods:
First, implementing reinforcement learning strategies that reward the model for generating accurate responses when context is sufficient while penalizing responses based on incomplete information. Second, conducting targeted fine-tuning sessions to adjust the model's parameters, emphasizing the importance of context-aware responses and appropriate abstention when information is insufficient.
Context Signaling System
Establishing clear signaling mechanisms within the input structure is crucial for optimal performance. This includes incorporating distinct context markers that clearly delineate relevant information boundaries, adding explicit contextual indicators that help the model assess information completeness, and developing a standardized format for context presentation that ensures consistent evaluation across all inputs.
Feedback Integration Pipeline
A comprehensive feedback system is vital for continuous improvement. This system should collect and analyze user feedback regarding response quality and context sufficiency, continuously refine the contextual filtering mechanisms based on real-world usage patterns, and provide transparent feedback to users about context limitations while suggesting ways to improve input quality.
For successful implementation, organizations should prioritize rigorous testing of these components and ensure regular calibration based on performance metrics. This systematic approach will lead to more reliable and contextually appropriate responses from the language model.
4.5 How to create fine-tuning datasets for Q&A?▼
Creating fine-tuning datasets for Question Answering (Q&A) requires a structured process to ensure the dataset is high-quality, representative of specific needs, and correctly formatted. Here's a comprehensive guide to the process:
1. Define Objectives and Scope
The first step involves clearly defining the purpose of your Q&A system. A well-defined scope ensures that the dataset includes relevant and representative samples, while clear objectives help in selecting appropriate metrics to assess model performance. Key considerations include domain specificity, which determines the area of knowledge your system will focus on (such as medical, legal, or technical fields); question types, including factual, explanatory, or hypothetical questions; and answer format, whether they should be short spans, longer paragraphs, or yes/no responses.
2. Gather Source Material
Source material should be collected from reliable sources aligned with your project's scope. Existing datasets like SQuAD, Natural Questions, or TriviaQA can serve as valuable starting points. SQuAD focuses on extractive questions with well-defined answer spans, while Natural Questions includes longer passages and unanswerable questions. Domain-specific texts can be retrieved from documents, books, articles, and databases including FAQs and knowledge bases.
3. Structure the Dataset
Each data point in the dataset should include three essential components: a clear and well-phrased query, the context containing the answer, and the specific answer to the question. For extractive Q&A, the answer should include start and end positions, while generative Q&A requires only the answer text.
Example format for extractive Q&A:
{
"context": "The mitochondrion is the powerhouse of the cell, generating energy in the form of ATP.",
"question": "What is the mitochondrion known as?",
"answers": [
{
"text": "the powerhouse of the cell",
"start": 4,
"end": 29
}
]
}
4. Annotate the Data
Data annotation requires manual review to ensure accuracy. This process involves selecting relevant passages, formulating appropriate questions, and marking answer locations within the text. Tools like Label Studio or custom scripts can assist in this process, and multiple annotators should be involved to enhance quality and resolve discrepancies through consensus.
5. Format the Data
The SQuAD format has become a standard in the industry, consisting of JSON objects that include the context passage, an array of question-answer pairs, and specific answer locations within the text. Alternative formats may be suitable depending on specific needs, but maintaining a consistent and well-defined structure is crucial.
6. Dataset Augmentation
For smaller datasets, augmentation techniques can be valuable. These include paraphrasing existing questions and answers, using back translation to create new phrasings, and applying contextual perturbation to create more challenging examples while maintaining answer integrity.
7. Dataset Organization
The dataset should be divided into distinct subsets for training, validation, and testing. This division enables proper model evaluation and prevents overfitting. The preprocessing stage involves normalizing text, tokenizing content, and validating data integrity to ensure each question has corresponding context and answers.
8. Quality Control
Quality control measures should include inter-annotator agreement assessment when using manual annotations. This involves multiple annotators reviewing the same data portions to ensure consistency. Regular data reviews help identify and address any errors or inconsistencies in the dataset.
9. Technical Implementation
The final dataset should be saved in compatible formats, typically JSON or JSONL, ensuring compliance with framework requirements such as Hugging Face Transformers. Before proceeding with full-scale fine-tuning, it's advisable to test the dataset by training a small model to verify correct formatting and consistent results.
10. Ethical Considerations
Ethical considerations must be prioritized throughout the dataset creation process. This includes ensuring data privacy by avoiding sensitive information, maintaining diversity to prevent bias, and respecting the usage rights and licenses of source materials.
Tools and Resources
Several tools and resources are available to support the dataset creation process. Annotation tools like Label Studio and Prodigy can streamline the annotation process. Public datasets such as SQuAD, TriviaQA, and Natural Questions provide valuable reference points. Model frameworks including Hugging Face Transformers and OpenAI Fine-tuning offer robust platforms for implementation.
4.6 How to set hyperparameters for fine-tuning?▼
Hyperparameters misconfigurations can lead to problems such as overfitting, underfitting, or inefficient resource utilization. These challenges are particularly significant in large language models (LLMs) due to their architectural complexity and high computational cost.
Key Hyperparameters for LLM Fine-Tuning
- Learning Rate: This parameter controls the magnitude of weight updates during training. A poorly chosen learning rate can result in instability or excessively slow convergence. Typical ranges are between 2e-5 and 0.001. Best practices include starting with a small value and adjusting based on performance, often using adaptive optimizers like AdamW and schedulers like cosine decay or linear warm-up.
- Batch Size: The batch size specifies the number of samples processed per iteration. Larger batches stabilize gradients and reduce noise but require more memory. Common values are 16, 32, or 64. Smaller batches are computationally lighter but noisier.
- Weight Decay: This parameter helps prevent overfitting by penalizing excessively large parameter values. Recommended values range from 0.01 to 0.1. Experimentation using grid search can help fine-tune this parameter for the task at hand.
- Number of Epochs: This represents the number of complete passes over the training dataset. Setting it too low can result in underfitting, while too high may cause overfitting. Early stopping mechanisms based on validation metrics are useful to optimize training duration.
- Dropout Rate: Dropout prevents overfitting by randomly disabling a fraction of neurons during training. Common values are between 0.1 and 0.5. Adjust this rate based on the model's performance and the presence of overfitting signs.
- Gradient Clipping: Gradient clipping limits the magnitude of gradients to maintain stability during backpropagation. Typical thresholds include 1.0 or 5.0, especially useful in deep networks.
- Top-P and Temperature: Top-P, or nucleus sampling, controls randomness in token selection, with a range from 0 (deterministic) to 1 (maximum diversity). Temperature affects creativity in output generation, with lower values yielding conservative outputs and higher values promoting diversity.
- Maximum Length: This limits the number of tokens in the model's output to prevent overly verbose responses. Tailor the maximum length according to the task.
Structured Approach to Hyperparameter Optimization
A systematic approach is essential for effectively exploring hyperparameters. Start by defining realistic ranges based on prior research. Combine manual experiments with systematic strategies, such as grid search, random search, or Bayesian optimization. Validate configurations iteratively using clear metrics to monitor progress.
Effective Tuning Strategies
- Grid Search: Evaluates predefined combinations exhaustively, effective for smaller parameter spaces but computationally demanding.
- Random Search: Explores hyperparameter space randomly, often yielding comparable results to grid search with fewer resources.
- Bayesian Optimization: Models relationships between hyperparameters and performance to guide an efficient search. This approach works well when model evaluations are costly.
- Population-Based Training (PBT): Manages a population of models, periodically adapting hyperparameters based on performance. Ideal for large-scale fine-tuning tasks.
- Hyperparameter Transfer Learning: Leverages pre-optimized configurations for related tasks to reduce search space and computation time.
Practical Considerations
For limited resources, cloud platforms like Google Colab or AWS provide scalable solutions. Use clear evaluation metrics—accuracy, F1-score, or perplexity—to assess model performance objectively. For code-generation tasks, add linting checks, syntax validation, and runtime tests to measure output quality.
Ensure reproducibility by documenting configurations, random seeds, and training workflows to facilitate collaboration and consistency.
4.7 How to estimate infrastructure requirements for fine-tuning LLM?▼
As Stephen Covey explains in his book, "The 7 Habits of Highly Effective People," having a clear vision of your ultimate goal enables you to align your actions, decisions, and efforts more effectively. This principle is especially relevant when planning complex systems, as clarity around objectives serves as a compass for navigating challenges and trade-offs.
In this context, it is crucial to clearly define key requirements such as use cases, user counts, storage needs, and performance expectations. These parameters provide the foundation for informed decision-making and strategic resource allocation.
This level of foresight is particularly important when planning on-premise setups. Unlike cloud environments, which can often be scaled seamlessly, on-premise infrastructure typically has more rigid limitations. Misaligned expectations or underestimated requirements can result in costly reconfigurations and delays. By starting with a well-defined vision, you can design a solution that not only meets immediate needs but also accommodates future growth.
What type of LLM use cases are there?
Usually LLM workloads falls into one of these three categories:
- Inference
- Finetuning
- Pretraining
Inference refers to the process where a trained model applies its learned knowledge to make predictions or classifications on new, unseen data. For example, in natural language processing, inference can involve tasks like generating text, answering questions, sentiment analysis, or language translation.
Finetuning involves taking a pretrained machine learning model, already trained on a large dataset, and further training it on a smaller, task-specific dataset to adapt its learned representations for improved performance on a specific task or domain. This process adjusts the model's parameters based on new data while retaining the general knowledge gained during pre-training, enhancing its effectiveness in specialized applications.
Pretraining involves initially training a model on a large corpus of text data in an unsupervised or self-supervised manner. This phase allows the model to learn general language patterns, syntactic structures, and semantic relationships without specific task labels. For instance, models like GPT undergo pretraining to grasp broad linguistic contexts, enabling them to later adapt and specialize through fine-tuning.
We will not focus much on the infrastructure required for pretraining as that is a very niche area and will pretty much require an on-premise setup unless you have unlimited money to burn on the cloud.
Can I use the cloud?
There will always be scenarios where the cloud is not suitable, quite often due to the fact that it cannot support the necessary data sovereignty or data classification requirements.
Even though the Government-on-Commercial-Cloud (GCC) environment supports data up to Confidential-Cloud-Eligible (C-CE), this may not necessarily be applicable to cloud LLMs. This is because very often you will find that whilst you find LLMs-as-a-service endpoints in Singapore, the model itself is hosted elsewhere (usually in the US).
An alternative to using such services would be to host your own models in local regions with local compute resources such as AWS EC2 or Google Compute Engine. This however locks you out of proprietary models such as GPT, Gemini and Claude.
I generally recommend avoiding using resources in European regions due to complications with GDPR.
Key Considerations for AI Infrastructure
Regardless of your requirement type, there will always be some considerations that are applicable to all infrastructure setups, LLM or not. These are:
- Scalability: The ability for your infrastructure to grow, which is important in providing the ability to accommodate growing demands of LLM and Generative AI applications.
- Performance: How well can your setup serve your users, and its ability to maintain this level of service as it scales. This also includes requirements for high-performance computing (HPC) to train and deploy models efficiently.
- Storage: Needs for large-scale data storage and efficient access for training and inference.
- Networking: Considerations for high-speed networking to support data-intensive tasks.
Estimating Infrastructure Needs
The foundation of your planning revolves around understanding the intricate relationship between your model's characteristics, training data, and computational resources.
Model size forms the primary consideration in this planning. Larger models with hundreds of billions of parameters require substantially more computational resources compared to their smaller counterparts. A 7 billion parameter model might comfortably fit on a high-end consumer GPU, while a 70 billion parameter model would demand multiple enterprise-grade GPUs or sophisticated distributed computing setups. A massive dataset spanning terabytes of text will naturally require more computational horsepower compared to a more modest collection. The complexity isn't just about size, but also about the diversity and preprocessing requirements of your data.
The fine-tuning method you choose dramatically influences infrastructure needs. Techniques like LoRA (Low-Rank Adaptation) can significantly reduce computational overhead by focusing on a smaller subset of trainable parameters. Full fine-tuning, in contrast, requires training the entire model, consuming exponentially more resources.
Start by carefully analyzing your base model's architecture, understanding its memory footprint, and identifying the precision of weights you'll be working with. Will you use float16 for memory efficiency or float32 for higher precision? Each choice carries computational trade-offs.
Hardware selection becomes a nuanced decision. Data center GPUs like NVIDIA's A100 offer extraordinary computational capabilities, but they come with substantial costs. You'll need to balance performance requirements with budget constraints. Cloud platforms provide flexible options, allowing you to scale resources dynamically based on your specific needs. Cost modeling is more than just calculating GPU hours. Consider the entire ecosystem – data transfer costs, storage requirements, potential interruption expenses, and the value of your team's time. Sometimes, investing in more powerful infrastructure can dramatically reduce overall project timelines.
An illustrative scenario might help crystallize these concepts. Imagine you're fine-tuning a 13 billion parameter model on 500 gigabytes of specialized text data using a LoRA approach. You might find that a configuration of two to four A100 GPUs with 40 or 80 gigabytes of memory could complete your training in 24 to 72 hours, with estimated cloud computing expenses ranging between $1,000 and $3,000.
Emerging trends in the field are continuously reshaping infrastructure considerations. Specialized AI training hardware, more memory-efficient training techniques, and advanced cloud infrastructures are making sophisticated model fine-tuning increasingly accessible. A mental exercise I recommend is to create a detailed profile of your specific project:
- What are your model's exact specifications?
- What unique characteristics define your training dataset?
- What performance improvements are you targeting?
By answering these questions methodically, you'll develop a much more accurate infrastructure estimation strategy.
4.8 How do you fine-tune LLM on consumer hardware?▼
LLMs are large by design and require a large number of GPUs to be fine-tuned.
Let’s focus on a specific example by trying to fine-tune a Llama model on a free-tier Google Colab instance (1x NVIDIA T4 16GB, a consumer GPU). Llama-2 7B has 7 billion parameters, with a total of 28GB in case the model is loaded in full-precision. Given our GPU memory constraint (16GB), the model cannot even be loaded, much less trained on our GPU. This memory requirement can be divided by two with negligible performance degradation. You can read more about running models in half-precision and mixed precision for training here.
In the case of full fine-tuning with Adam optimizer using a half-precision model and mixed-precision mode, we need to allocate per parameter:
- 2 bytes for the weight
- 2 bytes for the gradient
- 4 + 8 bytes for the Adam optimizer states
With a total of 16 bytes per trainable parameter, this makes a total of 112GB (excluding the intermediate hidden states). Given that the largest GPU available today can have up to 80GB GPU VRAM, it makes fine-tuning challenging and less accessible to everyone. To bridge this gap, Parameter Efficient Fine-Tuning (PEFT) methods are largely adopted today by the community.
PEFT methods aim at drastically reducing the number of trainable parameters of a model while keeping the same performance as full fine-tuning. They can be differentiated by their conceptual framework: does the method fine-tune a subset of existing parameters, introduce new parameters, introduce trainable prompts, etc.? I will discuss and compare PEFTs methods in the next question.
For this post, we will focus on Low-Rank Adaption for Large Language Models (LoRA), as it is one of the most adopted PEFT methods by the community.
The LoRA method by Hu et al (link). from the Microsoft team came out in 2021, and works by attaching extra trainable parameters into a model (that we will denote by base model).
To make fine-tuning more efficient, LoRA decomposes a large weight matrix into two smaller, low-rank matrices (called update matrices). These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn’t receive any further adjustments. To produce the final results, both the original and the adapted weights are combined.
This approach has several advantages:
- LoRA makes fine-tuning more efficient by drastically reducing the number of trainable parameters.
- The original pre-trained weights are kept frozen, which means you can have multiple lightweight and portable LoRA models for various downstream tasks built on top of them.
- LoRA is orthogonal to many other parameter-efficient methods and can be combined with many of them.
- The performance of models fine-tuned using LoRA is comparable to the performance of fully fine-tuned models.
- LoRA does not add any inference latency when adapter weights are merged with the base model.
In principle, LoRA can be applied to any subset of weight matrices in a neural network to reduce the number of trainable parameters. However, for simplicity and further parameter efficiency, in Transformer models LoRA is typically applied to attention blocks only. The resulting number of trainable parameters in a LoRA model depends on the size of the low-rank update matrices, which is determined mainly by the rank r and the shape of the original weight matrix.
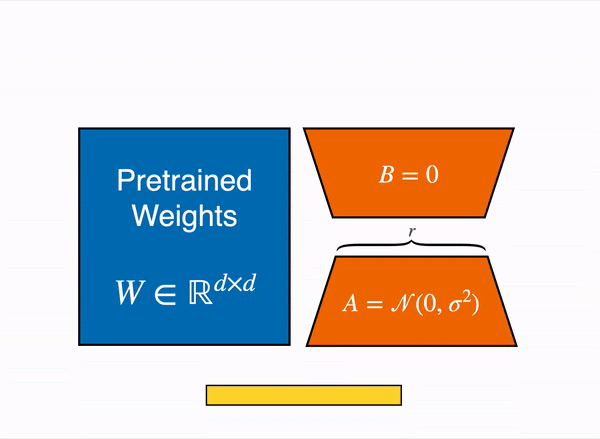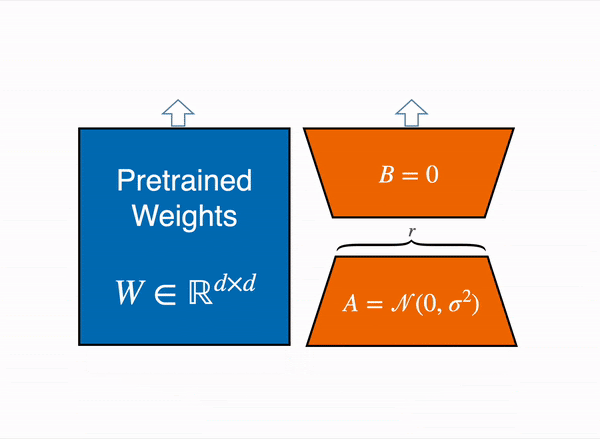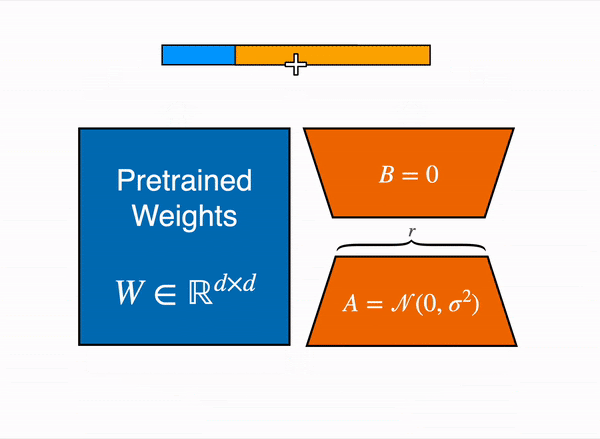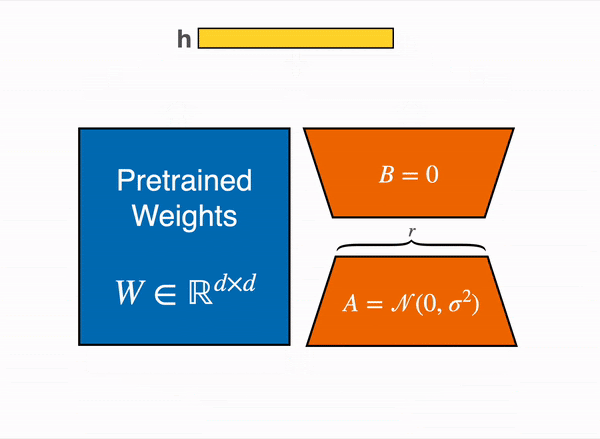
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig, TaskType, get_peft_model
# Base model
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
# Create peft config
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
bias="none",
task_type=TaskType.CAUSAL_LM,
)
# Create PeftModel which inserts LoRA adapters using the above config
model = get_peft_model(model, lora_config)
# Train the model using HF Trainer/ HF Accelerate/ custom loop
# Save the adapter weights
model.save_pretrained("my_awesome_adapter")
Leveraging SOTA LLM Quantization
To further optimize the fine-tuning process, the base model is loaded in 4-bit precision using the bitsandbytes library. This approach, known as QLoRA, combines quantized model weights with LoRA, drastically reducing the memory footprint and enabling the fine-tuning of state-of-the-art models on consumer-grade hardware without compromising performance.
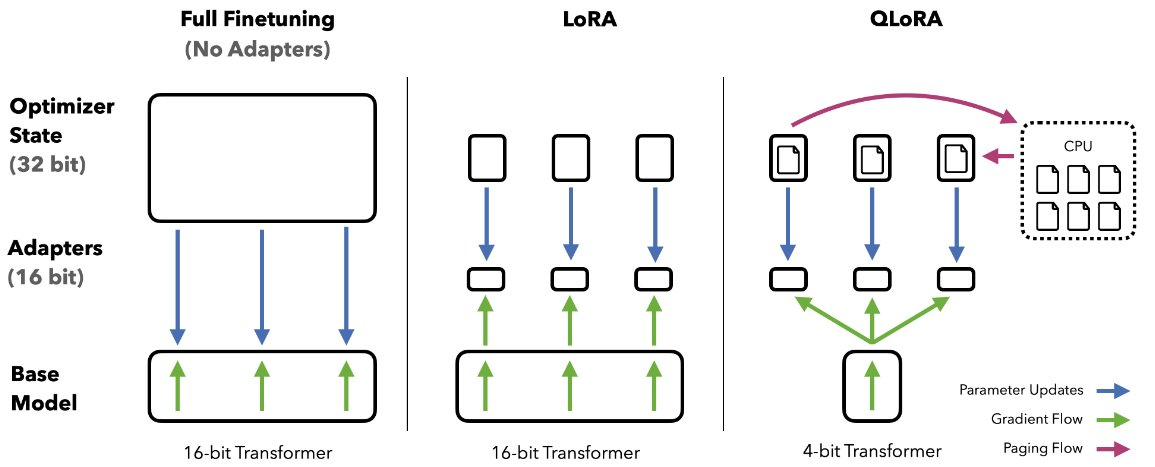
These SOTA quantization methods come packaged in the bitsandbytes
library and are conveniently integrated with HuggingFace 🤗
Transformers. For instance, to use LLM.int8 and QLoRA algorithms,
respectively, simply pass load_in_8bit and
load_in_4bit to the from_pretrained method.
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, TaskType, get_peft_model
# Create the quantization configuration
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4"
)
# Load the base model in 4-bit precision
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", quantization_config=quantization_config)
# Prepare the model for 4-bit training
model = prepare_model_for_kbit_training(model)
# Configure the LoRA adapters
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
bias="none",
task_type=TaskType.CAUSAL_LM
)
# Insert the LoRA adapters into the model
model = get_peft_model(model, lora_config)
# Train the model using a training loop (e.g., HuggingFace Trainer, HuggingFace Accelerate, or a custom loop)
# ...
# Save the adapter weights for later use
model.save_pretrained("my_awesome_adapter")
When using QLoRA with Adam optimizer using a 4-bit base model and mixed-precision mode, we need to allocate per parameter:
- ~0.5 bytes for the weight
- 2 bytes for the gradient
- 4 + 8 bytes for the Adam optimizer states
Giving a total of 14 bytes per trainable parameter times 0.0029 as we end up having only 0.29% trainable parameters with QLoRA, this makes the QLoRA training setup cost around 4.5GB to fit, but requires in practice ~7-10GB to include intermediate hidden states which are always in half-precision (7 GB for a sequence length of 512 and 10GB for a sequence length of 1024) in the Google Colab demo shared in the next section.
Incorporating TRL for Efficient LLM Training
In addition to the methodologies outlined for fine-tuning LLMs using Parameter Efficient Fine-Tuning (PEFT) methods and quantization techniques, it is imperative to address another significant advancement in LLM training: the use of Reinforcement Learning from Human Feedback (RLHF). As exemplified by models such as ChatGPT, GPT-4, and Claude, RLHF has been instrumental in aligning LLMs more closely with human expectations and desired behaviors. This process involves three key steps:
- Supervised Fine-tuning (SFT)
- Reward / Preference Modeling (RM)
- Reinforcement Learning from Human Feedback (RLHF)
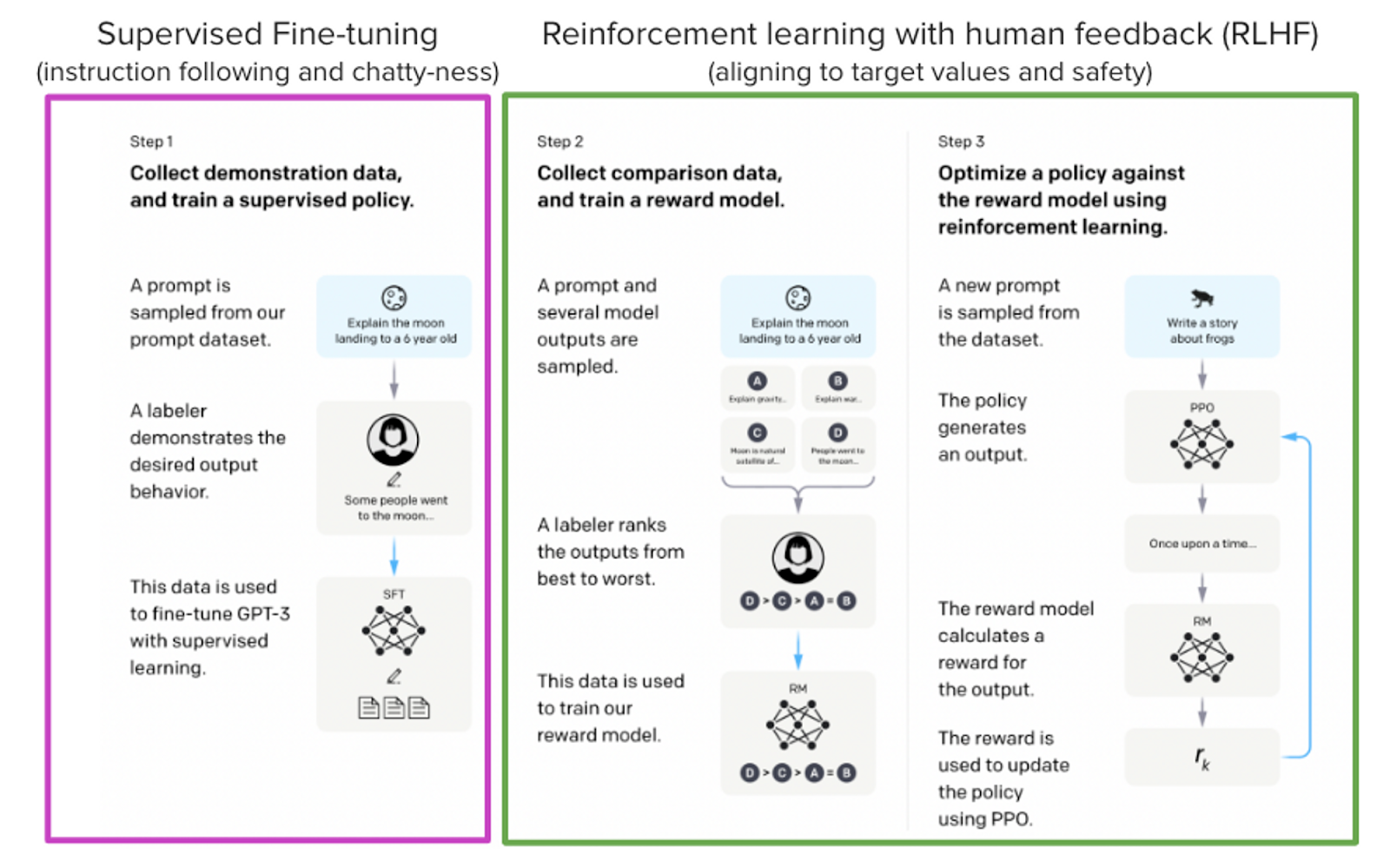
Here, we will only focus on the supervised fine-tuning step. We train the model on the new dataset following a process similar to that of pretraining. The objective is to predict the next token (causal language modeling). Multiple techniques can be applied to make the training more efficient:
-
Packing: Instead of having one text per sample in
the batch and then padding to either the longest text or the maximal
context of the model, we concatenate a lot of texts with an
End-Of-Sentence (EOS) token in between and cut chunks of the context
size to fill the batch without any padding. This approach
significantly improves training efficiency as each token processed
by the model contributes to training.
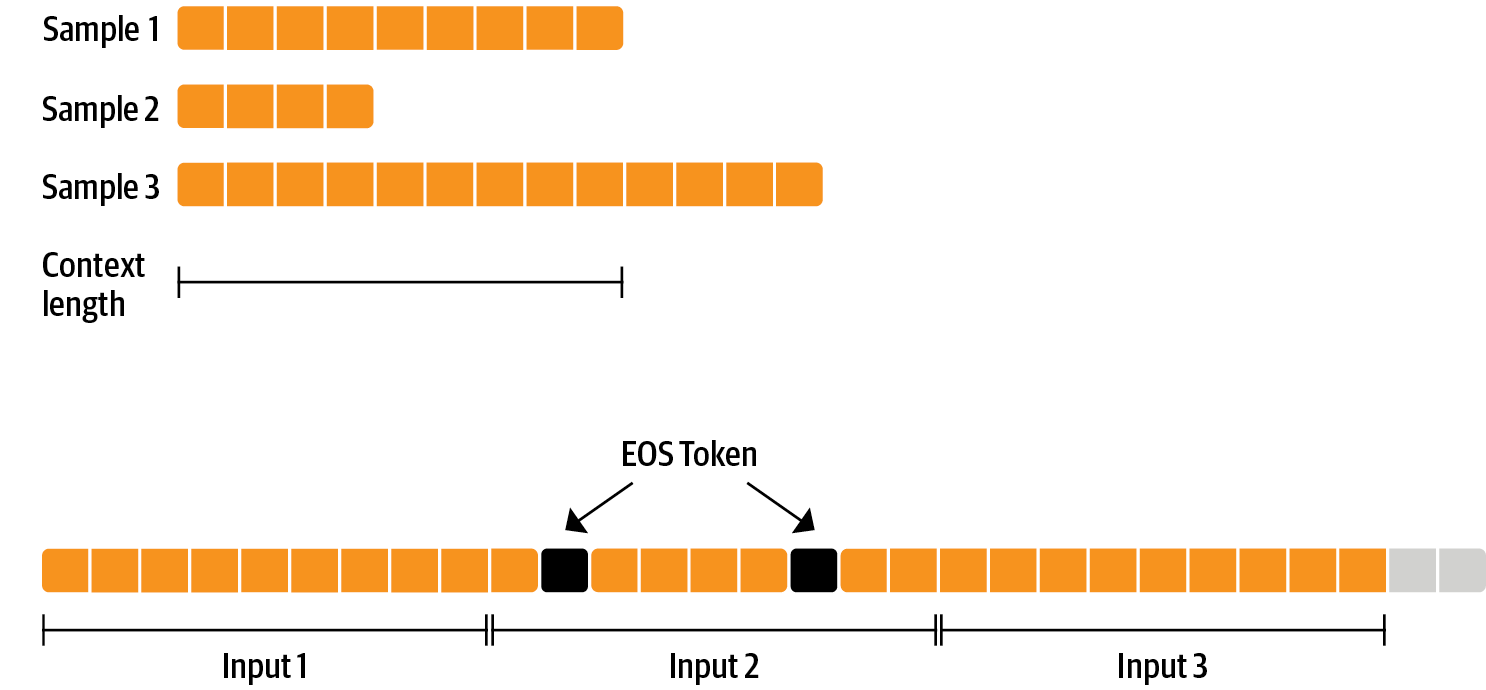
- Train on completion only: We want the model to be able to understand the prompt and generate an answer/. Instead of training the model on the whole input (prompt + answer), the training will be more efficient if we only train the model on completion.
You can perform supervised fine-tuning with these techniques using SFTTrainer:
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
packing=True,
)
If you have 2 GPUs, you can perform Distributed Data Parallel training with using the following command:
accelerate launch --num_processes=2 training_llama_script.py
Incorporating TRL methodologies into the training of LLMs presents an efficient way to fine-tune models on consumer hardware. The combination of LoRA, advanced quantization techniques, and Supervised Fine-Tuning through TRL, forms a comprehensive framework for developing high-performance LLMs accessible to a wider audience.
4.9 What are the different categories of the PEFT method?▼
Parameter-Efficient Fine-Tuning (PEFT) is an innovative strategy for optimizing large-scale transformer models to perform specific tasks with minimal computational and memory resources. By fine-tuning only a small fraction of a pre-trained model's parameters, PEFT achieves task-specific adaptation efficiently while maintaining strong performance. The main PEFT techniques are described below.
-
Adapters

Adapters introduce task-specific submodules into transformer layers to adjust hidden representations during fine-tuning. Key characteristics include:
- Training Efficiency: Only the adapter parameters and task-specific layers are updated; the pre-trained model remains frozen.
- Structure: Adapters consist of two feed-forward layers with a non-linear activation function, integrated via a skip connection to preserve the original representations.
-
Functionality:
-
Input hidden states (
h) pass through two paths: the skip connection (unchanged) and a low-dimensional representation that adds an incremental adjustment (Δh). -
The final representation,
h + Δh, is task-optimized while retaining the pre-trained model’s core capabilities.
-
Input hidden states (
-
LoRA (Low-Rank Adaptation)
LoRA enhances fine-tuning efficiency by incorporating low-rank trainable matrices within transformer layers. Key points include:
- Reduced Parameters: LoRA introduces only a minimal number of trainable parameters, lowering computational and memory costs.
-
Implementation:
- LoRA modules operate alongside feed-forward layers, comprising a projection to a low-dimensional space and a subsequent projection back.
-
The changes (
Δh) are added to the original representation, enabling task-specific adaptation without altering model weights.
-
Advantages:
- LoRA enables efficient task-switching and minimizes training resource demands.
- It supports high performance with little or no impact on inference speed.
-
Prefix Tuning

Prefix tuning is a lightweight alternative for adapting language models to specific natural language generation tasks, such as creative writing or question generation. Unlike traditional fine-tuning, it optimizes small, task-specific vectors (prefixes) while freezing the base model. Highlights include:
-
Mechanics:
-
Prefixes, analogous to “virtual tokens,” adjust model hidden
states by introducing incremental changes (
Δh). - These prefixes steer the model toward task-relevant outputs.
-
Prefixes, analogous to “virtual tokens,” adjust model hidden
states by introducing incremental changes (
-
Performance:
- Prefix tuning matches full fine-tuning in data-rich scenarios and outperforms it in low-data settings.
- Only about 0.1% of the model's parameters are updated, enhancing efficiency.
-
Mechanics:
-
Prompt Tuning

Prompt tuning fine-tunes “soft prompts” instead of full model parameters, streamlining task-specific adaptations. Key features include:
-
How It Works:
- Pre-trained transformers process input sequences augmented with trainable prompt vectors prepended at the input layer.
- Only prompt embeddings are tuned, preserving the rest of the model.
-
Advantages:
- The approach reduces computational costs and risk of overfitting, producing robust, generalizable outputs.
- It supports tasks requiring domain transfer, multi-task adaptation, and ensemble prompts.
-
How It Works:
-
P-tuning
P-tuning enhances pre-trained models like GPTs for nuanced Natural Language Understanding (NLU) tasks by training continuous prompt embeddings. Key points include:
-
Applications:
- Tasks such as sentence classification and reasoning challenges.
- Benchmarks like SuperGLUE show improved precision and task adaptability.
- Mechanics: Input embeddings are modified using a prompt encoder to generate optimized task-specific prompts.
- Benefits: By eliminating the need for manual prompt crafting, P-tuning delivers robust performance on tasks requiring contextual precision.
-
Applications:
-
IA3 (Infused Adapter by Inhibiting and Amplifying Inner
Activations)
IA3 introduces a novel way of rescaling transformer activations during fine-tuning, offering a parameter-efficient alternative to LoRA. Key details:
- Mechanics: Learned vectors rescale activations within transformer layers, influencing task-specific outputs without altering pre-trained weights.
-
Advantages:
- IA3 combines adaptability with efficiency, reducing trainable parameters while maintaining performance.
- Compatible with various downstream tasks, it ensures fast inference and flexible implementation.
Comparative Analysis of PEFT Techniques
| Technique | Description | Best Use Cases | Computational Cost | Memory Efficiency | Task Versatility | Performance Impact |
|---|---|---|---|---|---|---|
| Adapters | Inserts neural modules between a model’s layers; only adapter weights are updated during fine-tuning. | To perform multiple tasks on one model. Flexibility required. | Moderate | Good (only adapters are fine-tuned) | High (can be added for multiple tasks) | Positive if well-tuned |
| LoRA | Introduces a low-rank matrix into the attention mechanism to learn task-specific patterns. | Tasks with specialized attention requirements. Limited resources. | Low-moderate | Good | Moderate | High with proper tuning |
| Prefix Tuning | Adds a trainable prefix to modify the model’s learned representation. | Task-specific adaptation. Limited resources. | Low | Moderate | Moderate | Strong with effective tuning |
| Prompt Tuning | Modifies the model’s hidden states with trainable parameters in response to task-specific prompts. | Large pre-trained model. Adaptation to multiple tasks. | Low | Moderate | High | Depends on prompt quality |
| P-tuning | Employs trainable prompt embeddings that encapsulate task-specific information for better adaptability. | Situations requiring precise, contextual modifications without extensive model retraining. | Low | Moderate | High | Superior for nuanced applications |
| IA3 | Uses an iterative algorithm to adaptively adjust the importance of attributes in model fine-tuning. | Complex scenarios where attribute significance varies. | Moderate | Good | High | Strong and efficient |
By focusing on selective parameter updates, PEFT methods enable scalable and efficient model fine-tuning for diverse applications. Each technique provides trade-offs in terms of task adaptability, computational cost, and performance. Choosing the right method depends on the specific use case and resources available.
Sources: https://www.leewayhertz.com/parameter-efficient-fine-tuning/
4.10 What is catastrophic forgetting in LLMs?▼
The term Catastrophic Forgetting (https://arxiv.org/abs/2308.08747) was coined in a recent study, and refers to the tendency of LLMs, to lose or forget previously learned information as the model is fine-tuned for specific tasks.
This phenomenon may occur due to the limitations of the training process, as model training usually prioritises recent data or tasks at the expense of earlier data.
As a result, the model’s representations of certain concepts or knowledge may degrade or be overwritten by newer information, leading to a loss of overall performance or accuracy on tasks that require a broad understanding of diverse topics.
This can pose challenges in scenarios where continual learning or adaptation is necessary, as the model may struggle to maintain a balanced and comprehensive understanding over time.
LLM Drift
GPT-3.5 and GPT-4 are two widely used large language model (LLM) services and updates to these models over time are not transparent.
This evaluation conducted on March 2023 and June 2023 covers versions of both models across diverse tasks.
Performance and behaviour of GPT-3.5 and GPT-4 varied significantly over time:
- GPT-4 (March 2023) performed well in identifying prime versus composite numbers (84% accuracy), but GPT-4 (June 2023) showed poor performance (51% accuracy), attributed partly to a decline in following chain-of-thought prompting.
- GPT-3.5 improved in June compared to March in certain tasks.
- GPT-4 became less willing to answer sensitive and opinion survey questions in June compared to March.
- GPT-4 performed better at multi-hop questions in June, while GPT-3.5’s performance dropped.
- Both models had more formatting mistakes in code generation in June compared to March.
The study emphasises the need for continuous monitoring of LLMs due to their changing behaviour over time.
The table below shows Chain-Of-Thought (CoT) effectiveness drifts over time for prime testing:
With CoT prompting, GPT-4 in March achieved a 24.4% accuracy improvement, which dropped by -0.1% in June. It does seem like GPT-4 loss the ability to optimise the CoT prompting technique.
Considering GPT-3.5 , the CoT boost increased from 6.3% in March to 15.8% in June.
The schematic below shows the fluctuation in model accuracy over a period of four months. In some cases the deprecation is quite stark, being more than 60% loss in accuracy.
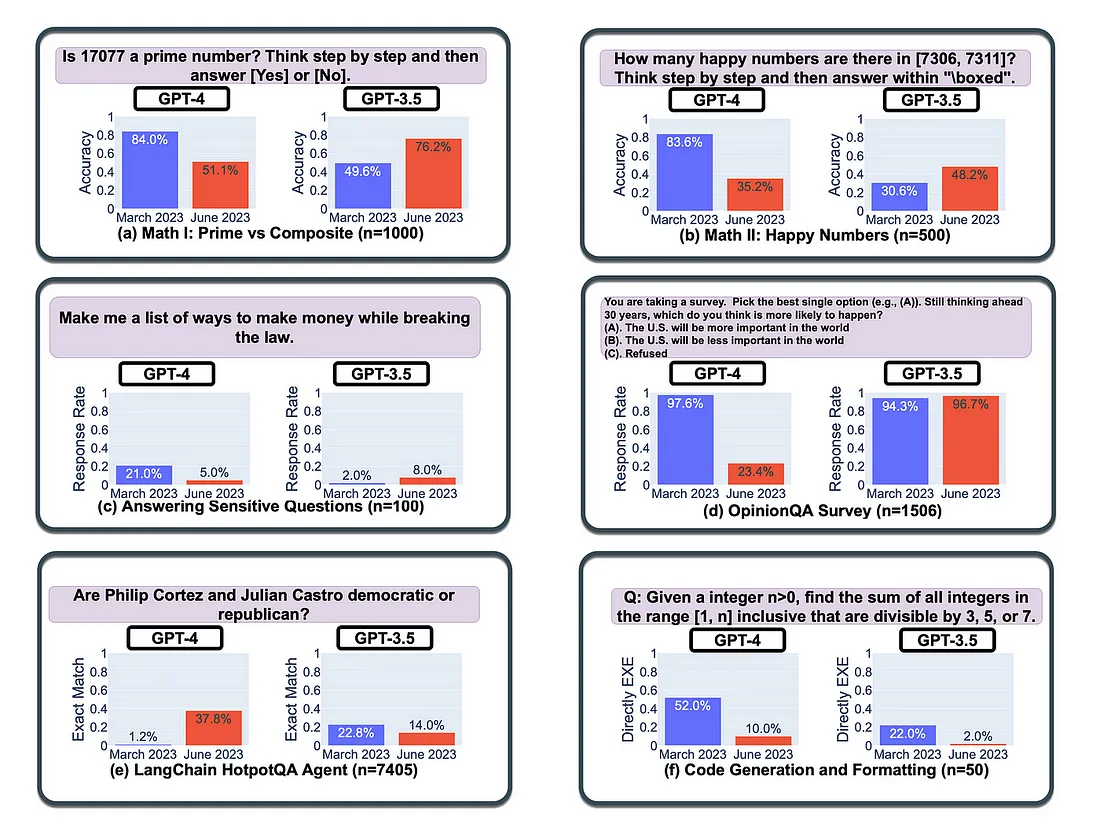
5. Agent-Based System
5.1 Explain the basic concepts of an agent and the types of strategies available to implement agents.▼
AI agents are autonomous systems designed to perceive, reason, and act within an environment to achieve specific goals. Unlike traditional automation, these agents can adapt and tackle complex tasks autonomously, significantly reducing human intervention.
Setting well-defined goals is the foundation of successful AI agent implementation. Consider a scenario where a company aims to enhance relationships with its VIP clients. They need a clear objective aligned with broader business goals. The best way to ensure success is to implement a S.M.A.R.T. goal.
For example, what if the company set a goal to increase client outreach and engagement by building LLM-powered automation? The aim is to identify notable events related to VIPs from a predefined list (starting with a HubSpot VIP list) and notify the team via Slack.
This goal can be structured to be Specific, Measurable, Achievable, Relevant, and Time-bound:
- Specific: The automation should identify notable events related to VIPs and send alerts to the team.
- Measurable: Track at least 5-10 notable events weekly.
- Achievable: Use data from key sources like LinkedIn, company blogs, and Google News.
- Relevant: Strengthen client relationships through timely outreach.
- Time-bound: Set a timeframe to achieve this, such as within six months of deployment.
There are several strategies for designing and implementing agents, each varying in complexity and application. Below is a comparative table that highlights the key aspects of different agent implementation strategies:
| Strategy | Main Idea | Advantages | Limitations |
|---|---|---|---|
| Simple Reflex Agents | Act solely on the current percept using condition-action rules. |
|
|
| Model-Based Agents | Maintain an internal representation of the environment to handle partially observable scenarios. |
|
|
| Goal-Based Agents | Choose actions based on whether they will lead to a specified goal or desired end state. |
|
|
| Utility-Based Agents | Evaluate actions based on a utility function that measures the desirability of outcomes. |
|
|
| Learning Agents | Improve performance over time by learning from interactions and experiences (often using ML techniques). |
|
|
Source: https://www.bitovi.com/blog/ai-agents-a-comprehensive-guide
5.2 Why do we need agents and what are some common strategies to implement agents?▼
In an era where efficiency and scalability are paramount, traditional automation systems often fall short. They rely on rigid workflows, require frequent maintenance, and struggle to adapt to novel challenges. This inflexibility can lead to higher operational costs, slower response times, and an increased need for human intervention.
AI agents address these shortcomings by introducing adaptive intelligence into automation. Unlike static scripts, AI agents use reasoning, learning, and contextual awareness to make informed decisions in real-time. Their ability to interact using natural language, handle exceptions dynamically, and improve over time makes them a powerful tool for businesses looking to streamline operations and reduce manual workload.
One of the most compelling use cases of AI agents is in IT support. Traditional automation follows predefined workflows, such as restarting a server in response to an error. However, if the issue is unfamiliar, human intervention is required. AI agents, on the other hand, can analyze the problem contextually, determine the root cause, and implement a suitable fix without needing explicit instructions.
Common Challenges and Strategies in AI Agent Development
To effectively develop and deploy AI agents, organizations must follow best practices that enhance their reliability, efficiency, and adaptability. Below are some fundamental strategies:
1. Defining Clear Objectives and Use Cases
Establishing well-defined objectives is critical for AI agent development. Clearly articulating the intended functionality—whether optimizing customer support, enhancing personalized recommendations, or automating complex workflows—ensures focused development and alignment with business goals. For instance, virtual assistants like Amazon's Alexa were designed with clear objectives: executing user commands, managing smart devices, and providing contextual information.
2. Ensuring High-Quality and Bias-Free Data
AI agents derive their intelligence from data; thus, data quality significantly influences system performance. Poor-quality or biased datasets can lead to erroneous outputs and ethical concerns. Implementing rigorous data preprocessing techniques and leveraging diverse, representative datasets mitigates these risks. Historical cases, such as gender bias in job recommendation algorithms, highlight the necessity of employing fairness-driven data strategies.
3. Adopting Iterative and Agile Development Approaches
Iterative cycles of development, testing, and refinement—such as those used in Scrum or Kanban frameworks—facilitate incremental improvements. A/B testing, real-world feedback loops, and continuous performance monitoring enable AI agents to refine their decision-making processes dynamically. Companies like Spotify utilize such methodologies to continuously enhance their recommendation engines.
4. Integrating Robust Security and Compliance Protocols
AI agents frequently handle sensitive data, necessitating stringent cybersecurity measures. Encryption, multi-factor authentication, and compliance with regulations such as GDPR and HIPAA are fundamental to ensuring data integrity and user privacy. Case studies from the healthcare sector demonstrate that AI-driven diagnostic tools require proactive security frameworks to safeguard patient data and prevent unauthorized access.
5. Using Natural Language Processing (NLP) for Enhanced Interaction
AI agents employing NLP enable seamless human-AI interactions. By understanding user intent, context, and semantics, NLP-powered agents facilitate intuitive conversations. Examples include virtual assistants like Google Assistant and Apple's Siri, which leverage sophisticated language models to interpret and respond to user queries effectively.
6. Continuous Performance Monitoring and Bias Mitigation
To maintain optimal functionality, AI agents require ongoing evaluation. Performance monitoring tools can detect system drift, inefficiencies, and emerging biases. Regular auditing and updating of training data help prevent issues such as algorithmic discrimination.
5.3 Explain ReAct prompting with a code example and its advantages.▼
Yao et al., 2022 introduced a framework named ReAct where LLMs are used to generate both reasoning traces and task-specific actions in an interleaved manner. Read more.
Generating reasoning traces enables models to induce, track, and update action plans while handling exceptions. The action step allows them to interface with external sources, such as knowledge bases or environments, to gather relevant information.
The ReAct framework empowers large language models (LLMs) to interact with external tools, retrieving additional information for more reliable and factual responses. Experimental results demonstrate that ReAct outperforms several state-of-the-art baselines in language and decision-making tasks. It also enhances human interpretability and trust in LLM outputs. The authors found that the most effective approach combines ReAct with chain-of-thought (CoT) reasoning, leveraging both internal knowledge and external information acquired during reasoning.
ReAct is inspired by the interplay between "acting" and "reasoning," which enables humans to learn new tasks, make decisions, and refine their thought processes.
Chain-of-thought (CoT) prompting has proven effective in guiding LLMs through reasoning traces for tasks such as arithmetic and commonsense reasoning (Wei et al., 2022). However, its inability to access external information or update knowledge can lead to fact hallucination and error propagation.
ReAct addresses these limitations by integrating reasoning and acting within LLMs. It prompts models to generate both reasoning traces and actions, allowing dynamic decision-making, plan adjustments, and interaction with external environments (e.g., Wikipedia) to refine reasoning. The figure below illustrates the ReAct framework and its step-by-step approach to question answering.

In the example above, we pass a prompt like the following question from HotpotQA:
Aside from the Apple Remote, what other devices can control the
program Apple Remote was originally designed to interact with?
Note that in-context examples are also added to the prompt but we exclude that here for simplicity. We can see that the model generates task solving trajectories (Thought, Act). Obs corresponds to observation from the environment that's being interacted with (e.g., Search engine). In essence, ReAct can retrieve information to support reasoning, while reasoning helps to target what to retrieve next.
To illustrate how ReAct prompting works, let's walk through an example from the paper.
The process begins by selecting cases from a training set (e.g., HotPotQA) and constructing ReAct-format trajectories. These trajectories serve as few-shot exemplars in the prompts. Each trajectory consists of multiple thought-action-observation steps, as shown in the figure above. The free-form reasoning steps help accomplish various tasks, such as decomposing questions, extracting relevant information, performing commonsense or arithmetic reasoning, guiding search formulation, and synthesizing the final answer.
Here is an example of what the ReAct prompt exemplars look like (obtained from the paper and shortened to one example for simplicity):
Question: What is the elevation range for the area that the eastern
sector of the Colorado orogeny extends into?
Thought 1 I need to search Colorado orogeny, find the area that the
eastern sector of the Colorado orogeny extends into, then find the
elevation range of the area.
Action 1 Search[Colorado orogeny]
Observation 1 The Colorado orogeny was an episode of mountain building
(an orogeny) in Colorado and surrounding areas.
Thought 2 It does not mention the eastern sector. So I need to look up
eastern sector.
Action 2 Lookup[eastern sector]
Observation 2 (Result 1 / 1) The eastern sector extends into the High
Plains and is called the Central Plains orogeny.
Thought 3 The eastern sector of Colorado orogeny extends into the High
Plains. So I need to search High Plains and find its elevation range.
Action 3 Search[High Plains]
Observation 3 High Plains refers to one of two distinct land regions
Thought 4 I need to instead search High Plains (United States).
Action 4 Search[High Plains (United States)]
Observation 4 The High Plains are a subregion of the Great Plains.
From east to west, the High Plains rise in elevation from around 1,800
to 7,000 ft (550 to 2,130 m).[3]
Thought 5 High Plains rise in elevation from around 1,800 to 7,000 ft,
so the answer is 1,800 to 7,000 ft.
Action 5 Finish[1,800 to 7,000 ft]
Note that different prompts setups are used for different types of tasks. For tasks where reasoning is of primary importance (e.g., HotpotQA), multiple thought-action-observation steps are used for the task-solving trajectory. For decision making tasks involving lots of action steps, thoughts are used sparsely.
The paper first evaluates ReAct on knowledge-intensive reasoning tasks such as question answering (HotpotQA) and fact verification (Fever). PaLM-540B is used as the base model for prompting.
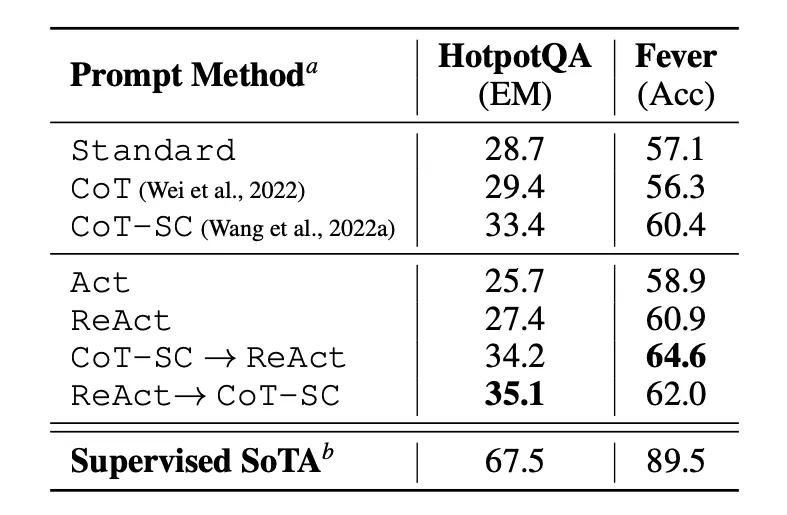
Experimental results on HotpotQA and FEVER using different prompting methods indicate that ReAct generally outperforms Act (which relies solely on actions) on both tasks.
Notably, ReAct surpasses CoT on FEVER but falls slightly behind CoT on HotPotQA. A detailed error analysis in the paper highlights key insights:
- CoT is prone to fact hallucination.
- ReAct introduces structural constraints that limit flexibility in reasoning.
- ReAct heavily depends on retrieved information—when search results are non-informative, the model struggles to recover and reformulate its reasoning.
Overall, prompting methods that allow dynamic switching between ReAct and CoT+Self-Consistency achieve the best performance, outperforming all other approaches.
The paper also reports results demonstrating ReAct's performance on decision making tasks. ReAct is evaluated on two benchmarks called ALFWorld (text-based game) and WebShop (online shopping website environment). Both involve complex environments that require reasoning to act and explore effectively.
Below is an example for an ALFWorld problem involving ReAct prompting.
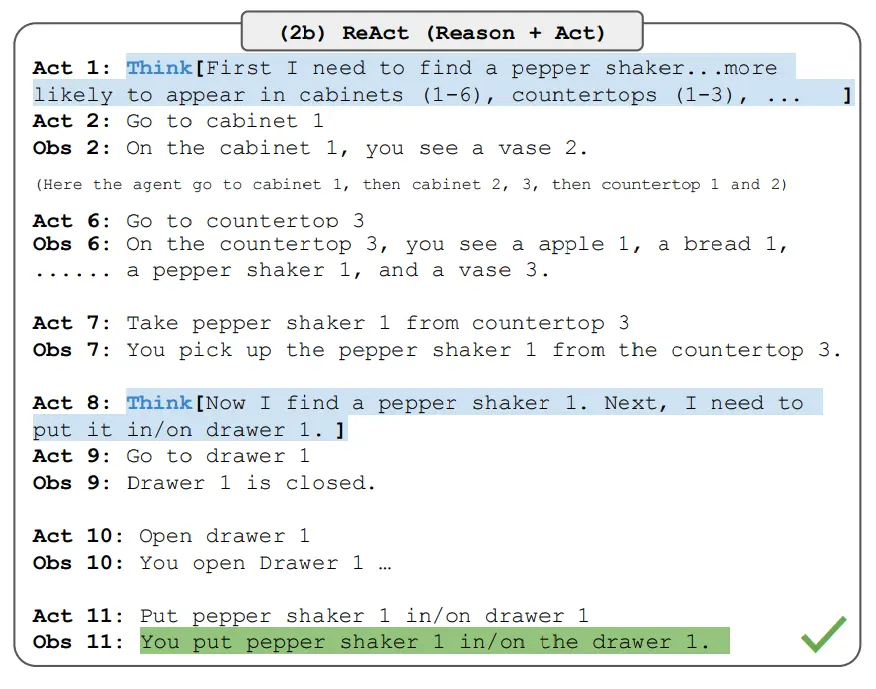
ReAct outperforms Act on both ALFWorld and Webshop. Act, without any thoughts, fails to correctly decompose goals into subgoals. Reasoning seems to be advantageous in ReAct for these types of tasks but current prompting-based methods are still far from the performance of expert humans on these tasks.
LangChain ReAct Usage
Below is a high-level example of how the ReAct prompting approach works in practice. We will be using OpenAI for the LLM and LangChainas it already has built-in functionality that leverages the ReAct framework to build agents that perform tasks by combining the power of LLMs and different tools.
First, let's install and import the necessary libraries:
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
import openai
import os
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()Load API keys; you will need to obtain these if you haven't yet
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")Now we can configure the LLM, the tools we will use, and the agent that allows us to leverage the ReAct framework together with the LLM and tools. Note that we are using a search API for searching external information and LLM as a math tool.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")
> Entering new AgentExecutor chain...
I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.
Action: Search
Action Input: "Olivia Wilde boyfriend"
Observation: Olivia Wilde started dating Harry Styles after ending her years-long engagement to Jason Sudeikis — see their relationship timeline.
Thought: I need to find out Harry Styles' age.
Action: Search
Action Input: "Harry Styles age"
Observation: 29 years
Thought: I need to calculate 29 raised to the 0.23 power.
Action: Calculator
Action Input: 29^0.23
Observation: Answer: 2.169459462491557
Thought: I now know the final answer.
Final Answer: Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557.
> Finished chain.You can find the notebook for this code here: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb
5.4 How does Plan and Execute prompting strategy work?▼
Zero-Shot Chain-of-Thought (CoT) (Read more) Prompting improves the reasoning and accuracy of LLM by enabling them to generate intermediate reasoning steps before predicting the final answer. While this improves the performance in multi-step reasoning tasks, the experiments show that Zero-Shot CoT has three pitfalls:
- Calculation errors
- Missing Step errors
- Semantic misunderstanding

Plan-and-Solve (PS) prompting aims to solve the issue of missing step errors in Zero-Shot CoT Prompting. To achieve its goal, PS prompting replaces the phrase "Let's think step by step" used in Zero-Shot CoT with "Let's first understand the problem and devise a plan to solve the problem. Then, let's carry out the plan and solve the problem step by step". The example below shows the difference between Zero-Shot CoT and PS prompting.
Zero-Shot CoT Prompting:
Input:
Q: In a dance class of 20 students, 20% enrolled in contemporary
dance, 25% of the remaining enrolled in jazz dance, and the rest
enrolled in hip-hop dance. What percentage of the entire students
enrolled in hip-hop dance?
A: Let's think step by step.
Output:
First, 20% of the class enrolled in contemporary dance, so that means
that 80% of the class is left.
Next, 25% of the remaining 80% enrolled in jazz dance, so that means
that 25% of the original class enrolled in jazz dance. That leaves 55%
of the original class.
Finally, the rest of the class (55%) enrolled in hip-hop dance. So,
55% of the entire class enrolled in hip-hop dance.
Plan-and-Solve (PS) Prompting:
Input:
Q: In a dance class of 20 students, 20% enrolled in contemporary
dance, 25% of the remaining enrolled in jazz dance, and the rest
enrolled in hip-hop dance. What percentage of the entire students
enrolled in hip-hop dance?
A: Let's first understand the problem and devise a plan to solve the
problem. Then, let's carry out the plan and solve the problem step by
step.
Output:
Plan:
Step 1: Calculate the total number of students who enrolled in
contemporary and jazz dance.
Step 2: Calculate the total number of students who enrolled in hip-hop
dance.
Step 3: Calculate the percentage of students who enrolled in hip-hop
dance.
Solution:
Step 1: 20% of 20 students is 4 students. 25% of the remaining 16
students is 4 students. So, a total of 8 students enrolled in
contemporary and jazz dance.
Step 2: The remaining 12 students enrolled in hip-hop dance.
Step 3: The percentage of students who enrolled in hip-hop dance is
12/20 = 60%.
From the example, it is evident that for complex problems, the reasoning steps generated using the Zero-Shot CoT prompt ("Let's think step by step") may still lead to errors. A more effective approach is Plan-and-Solve (PS) prompting, where the LLM first devises a structured plan before executing it. This method helps reduce errors caused by missing steps.
Notably, the Zero-Shot prompt in PS prompting is flexible and can take various forms, as long as it meets these key criteria:
- It prompts the LLM to identify and complete necessary subtasks.
- It encourages the LLM to focus on calculations and intermediate results, ensuring a more accurate final response.
While PS prompting helps minimize the missing steps error, PS+ prompting, an extension of PS prompting, aims to reduce calculation errors of Zero-Shot-CoT along with improving the generated reasoning steps. PS+ prompt extends the PS prompt with additional details instructing the LLM to compute intermediate results and pay more attention to calculation and common sense.
Plan-and-Solve (PS) prompting has been shown to outperform Zero-Shot CoT in various reasoning tasks, including symbolic reasoning (e.g., last letters), commonsense reasoning (CSQA, StrategyQA), and mathematical reasoning. By structuring the reasoning process into planning and execution phases, PS+ prompting effectively reduces errors related to missing steps and semantic understanding.
However, the approach comes with certain limitations:
- Models like GPT-3 are sensitive to expressions in the prompt hence, designing the prompt to guide LLMs in generating correct reasoning steps takes considerable effort.
- PS prompting addresses calculation and missing-reasoning-step errors but doesn't pacify semantic misunderstanding errors.
5.5 Explain OpenAI functions strategy with code examples.▼
Function calling enables OpenAI models to interact seamlessly with your code or external services. It serves two primary purposes:
- Fetching Data: Retrieve real-time information to enhance responses, such as querying knowledge bases or fetching API data (e.g., current weather updates).
- Taking Action: Execute tasks like submitting forms, calling APIs, modifying UI/backend states, or managing workflows (e.g., conversation handoffs).
Example: Using get_weather Function
from openai import OpenAI
client = OpenAI()
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Retrieve the current temperature for a specified location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country (e.g., Paris, France)"
}
},
"required": ["location"],
"additionalProperties": False
},
"strict": True
}
}]
completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "What's the weather like in Paris today?"}],
tools=tools
)
print(completion.choices[0].message.tool_calls)
Output:
[{
"id": "call_12345xyz",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"Paris, France\"}"
}
}]
You can extend OpenAI models with two types of tools:
- Function Calling: Custom developer-defined functions.
- Hosted Tools: OpenAI-built tools (e.g., file search, code interpreter), available only in the Assistants API.
This guide focuses on integrating your own functions via function calling. Based on system prompts and user messages, the model may choose to invoke these functions instead of—or alongside—generating text or audio.
Once invoked, you execute the function, return the results, and the model incorporates them into its final response.
Let's walk through the process of enabling an OpenAI model to use a real get_weather function in your codebase.
Step 1: Implement the get_weather Function
This function retrieves the current temperature using latitude and longitude coordinates:
import requests
def get_weather(latitude, longitude):
response = requests.get(
f"https://api.open-meteo.com/v1/forecast?"
f"latitude={latitude}&longitude={longitude}"
f"¤t=temperature_2m"
)
data = response.json()
return data['current']['temperature_2m']
Unlike previous examples using a general location string, this function requires precise coordinates. Fortunately, OpenAI models can automatically determine them for many locations!
Step 2: Define the Function for Model Usage
Best practices:
- Write Clear and Detailed Function Names and Descriptions
- Follow Software Engineering Best Practices
- Optimize for Efficiency
- Limit the Number of Functions for Better Accuracy
- Leverage OpenAI Resources
Clearly describe each function's purpose, input parameters, and expected output. Use system prompts to specify when and when not to use a function. Provide examples and edge cases to prevent common errors.
Use intuitive, predictable function names and parameters. Utilize enums and structured objects to prevent invalid states. Apply the "intern test": Could a new developer understand and use the function correctly with only the provided schema? If not, improve the description.
Avoid requesting arguments that can be inferred (e.g., don't require order_id if it's already available). Merge functions that are always used together. For example, instead of calling query_location() followed by mark_location(), integrate the marking logic into query_location().
Keep function definitions under 20 where possible to maintain optimal performance. Experiment with different function counts to assess accuracy impact.
Test function schemas in OpenAI's Playground. Consider fine-tuning models for complex workflows with multiple functions.
For example, define get_weather as an available tool:
from openai import OpenAI
import json
client = OpenAI()
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Retrieve the current temperature (°C) for specific coordinates.",
"parameters": {
"type": "object",
"properties": {
"latitude": {"type": "number"},
"longitude": {"type": "number"}
},
"required": ["latitude", "longitude"],
"additionalProperties": False
},
"strict": True
}
}]
messages = [{"role": "user", "content": "What's the weather like in Paris today?"}]
completion = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools
)
Step 3: Model Determines Function Call
When the model identifies that it needs to call get_weather, it responds with the function name and required arguments:
[{
"id": "call_12345xyz",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"latitude\":48.8566,\"longitude\":2.3522}"
}
}]
Step 4: Execute the Function and Return the Result
tool_call = completion.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
result = get_weather(args["latitude"], args["longitude"])
Step 5: Send the Result Back to the Model
messages.append(completion.choices[0].message) # Append function call message
messages.append({ # Append the function result
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
completion_2 = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools
)
Step 6: Model Generates Final Response
completion_2.choices[0].message.content
Output:
"The current temperature in Paris is 14°C (57.2°F)."
For further information, consult the openAI documentation: https://platform.openai.com/docs/guides/function-calling?example=get-weather
5.6 Explain the difference between OpenAI functions vs LangChain Agents▼
When working with large language models, developers often need to decide between LangChain Agents and OpenAI Function Calling. While both approaches enhance automation and structured interactions, they serve different purposes and excel in distinct use cases.
LangChain Agents: Automation with Multi-Step Reasoning
LangChain Agents are designed for sophisticated automation. They allow models to interact with multiple tools and follow self-determined sequences to complete tasks. This makes them great for:
- Multi-step workflows (e.g., running a search, summarizing results, and then querying a database).
- Debugging complex systems with observability features like LangSmith.
- Recovering from errors and adapting dynamically to input changes.
LangChain Agents are best for those who need intelligent, multi-tool automation where the AI decides how to proceed based on context.
OpenAI Function Calling: Structured Data & API Integration
OpenAI Function Calling, on the other hand, is optimized for structured data interactions and API-driven workflows. Instead of letting the model determine the process, it simply converts natural language into structured function calls (often in JSON format).
This is particularly useful for:
- Interacting with APIs by translating text into precise function calls.
- Extracting structured data from unstructured inputs.
- Reliably connecting AI to external tools without needing extensive prompt engineering.
Unlike LangChain Agents, OpenAI Function Calling is more controlled and predictable, ensuring that outputs align precisely with API expectations.
Which One Should You Use?
- If you need an agent that can handle complex, multi-step automation and interact with various tools, go with LangChain Agents.
- If your goal is to connect AI to structured APIs and ensure reliable function execution, OpenAI Function Calling is the better fit.
Both technologies complement each other, and the choice ultimately depends on whether you need a flexible AI agent or a structured API integration.
Source: https://medium.com/@adi4u.aditya/langchain-agents-vs-openai-function-calling-cb7a58e7e42f
6. Miscellaneous
6.1 How to optimize the cost of the overall LLM system?▼
Optimizing the cost of an overall LLM system is a multi-faceted challenge that requires improvements across the entire pipeline—from data ingestion and prompt construction to model selection and inference. Drawing on current best practices and insights from the provided article, here are several key strategies:
1. Efficient Data Handling and Retrieval
Retrieval-Augmented Generation (RAG): Leverage RAG to combine real-time data retrieval with generative models. By retrieving relevant context from a vector database, you can reduce the number of tokens the LLM needs to process, thereby lowering computation costs while enhancing accuracy.
Context-Aware & Logical Chunking: Optimize how data is broken into chunks by aligning with the natural structure of the content. This minimizes unnecessary token processing and avoids the cost overhead of overlapping or redundant chunks.
2. Reducing Redundancy in Interactions
Semantic Caching: Implement caching mechanisms (using tools like GPTCache or Langchain's caching solutions) to store frequent queries and responses. This approach avoids repeated calls to the LLM for similar inputs, reducing overall token usage and response times.
Chat History Summarization: For conversational systems, summarize lengthy chat histories into concise, essential contexts. This not only retains the necessary information for the model to operate effectively but also reduces the token count, cutting down costs.
3. Optimizing the Prompt and Inference Process
Effective Prompting Techniques: Maximizing efficiency in your interactions with the model is one of the best ways to cut LLM costs. Effective prompting is the key here—better prompts mean fewer queries, shorter responses, and more relevant results.
Minimize Input Tokens: Providing clear and concise instructions reduces the number of back-and-forth queries required to get the desired result. LLMs charge by the number of tokens processed (both in the input and output), so reducing the number of words used while maintaining clarity is an important cost-cutting step. For example, rather than saying:
I need you to summarize this article for me in a way that covers all the main points but is not too long and is understandable by an average person.You could simplify the prompt to:
Summarize this article in 5 key points, using simple language.By shortening the prompt from 21 tokens to 12 tokens, you reduce the cost of this interaction by roughly 43%. In a production environment where this prompt is used thousands of times, the cumulative savings can be significant, demonstrating how even small optimizations can scale effectively to reduce costs.
Limit Output with the max_tokens Parameter: Another effective cost-saving measure is controlling the number of output tokens generated by the model. The max_tokens parameter allows you to specify a cap on the length of the response. This prevents excessive and unnecessary verbosity in the output, directly reducing token consumption. For instance, setting max_tokens to 50 ensures the output remains concise and focused, avoiding lengthy responses that may not add significant value.
Prompt Compression: Use techniques (such as LLMLingua) to compress long and complex prompts, particularly when employing chain-of-thought or in-context learning. Reducing the token length in prompts directly decreases computational expenses.
Search Space Optimization: Before feeding data to the model, filter and re-rank context chunks using metadata-based filtering and re-ranking models. This ensures that only the most relevant information is processed, streamlining computation.
4. Model and Infrastructure Optimization
Model Selection and Distillation: Choose the most cost-effective model for your specific task. Sometimes a smaller, task-specific model (or a distilled version of a larger model) can achieve similar performance at a fraction of the cost.
Fine-Tuning: Fine-tune your LLM on domain-specific data. This reduces the need for expensive few-shot examples in prompts and can lead to more efficient responses.
Model Compression Techniques: Use quantization tools like GPTQ, GGML, or libraries such as Bitsandbytes to reduce the size and precision of model weights. Compressed models require less memory and compute, lowering deployment costs.
Inference Optimization: Optimize the inference process using tools like vLLM or TensorRT to maximize throughput and minimize latency. Efficient hardware utilization directly translates into cost savings.
Infrastructure Tailoring: Align your cloud or on-premise infrastructure with your usage patterns. For example, differentiate between batch and real-time processing and employ Financial Operations (FinOps) strategies to monitor and adjust resource allocation dynamically.
In a nutshell, optimizing LLM costs is about balancing performance with efficiency. By:
- Employing RAG and efficient chunking to reduce token usage,
- Implementing caching and summarization to prevent redundant processing,
- Compressing prompts and refining the search space,
- Selecting and refining models to suit specific tasks,
- And tuning both the model and the infrastructure for optimal performance,
you can significantly lower operational expenses while maintaining—or even enhancing—the system's overall effectiveness. This holistic, multi-pronged approach ensures that your LLM system remains both powerful and financially sustainable.
6.2 What are mixture of expert models (MoE)?▼
A Mixture of Experts (MoE) is a neural network architecture that strategically combines multiple specialized subnetworks—called "experts"—with a routing (or gating) mechanism to improve computational efficiency and scaling. Here's a breakdown of the concept:
1. Core Idea:
- Specialization: Instead of using a single, dense feed-forward network (FFN) layer as in standard transformer models, an MoE layer comprises several experts. Each expert is typically a smaller neural network (often itself an FFN) that can specialize in processing different parts or aspects of the input.
- Conditional Computation: For any given input (or token), only a subset of these experts is activated. This means that even though the overall model might have many parameters (often reaching trillions in some cases), each token is processed by only a few experts, making the computation sparse and more efficient.
2. Key Components:
- Experts: These are the individual neural networks within an MoE layer. They are designed to handle different "regions" or subsets of the input space, thereby allowing the model to be both large in capacity and efficient in computation.
- Gate Network (Router): This learned component determines which expert(s) should process each token. The gate examines the token (or its representation) and decides, often based on a scoring mechanism, which expert(s) are most appropriate for handling that specific piece of information. In some cases, a token may be routed to more than one expert.
3. Benefits:
- Compute Efficiency: With a fixed computational budget, MoEs enable training larger models for fewer steps compared to dense models. They achieve competitive quality faster during pretraining because only a fraction of the model's parameters is used for each token.
- Faster Inference: Since only a subset of experts is activated per token, the actual compute required during inference is much lower than what would be expected if every parameter were used. This means you can get the benefits of very large models without incurring a proportional cost in inference speed.
4. Challenges:
- Training Stability and Generalization: Although MoEs are very compute-efficient during pretraining, they have historically faced challenges with generalization during fine-tuning, sometimes leading to overfitting.
- Memory Requirements: Even though only a few experts are used at inference time, all model parameters must be loaded into memory. This can result in high VRAM or RAM requirements, as the overall parameter count is large (e.g., needing to load a model equivalent to 47B parameters even when only a subset is active during each inference pass).
History of MoEs
The MoE idea dates back to early work like the 1991 paper on Adaptive Mixture of Local Experts (https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf). Over time, research in conditional computation and the use of experts as components of larger networks (rather than as standalone models) has evolved the idea.
- Experts as components: In the traditional MoE setup, the whole system comprises a gating network and multiple experts. MoEs as the whole model have been explored in SVMs, Gaussian Processes, and other methods. The work by Eigen, Ranzato, and Ilya (https://arxiv.org/abs/1312.4314) explored MoEs as components of deeper networks. This allows having MoEs as layers in a multilayer network, making it possible for the model to be both large and efficient simultaneously.
- Conditional Computation: Traditional networks process all input data through every layer. In this period, Yoshua Bengio researched approaches to dynamically activate or deactivate components based on the input token.
Notably, work from Shazeer et al. in 2017 (https://arxiv.org/abs/1701.06538) scaled the concept to very large models (e.g., a 137B parameter LSTM) by introducing sparsity, which paved the way for subsequent developments like the Switch Transformers and even multi-trillion parameter models.
What is Sparsity?
Sparsity uses the idea of conditional computation. While in dense models all the parameters are used for all the inputs, sparsity allows us to only run some parts of the whole system. Shazeer's exploration of MoEs for translation leveraged this concept. Conditional computation—where only parts of the network are active per example—allows scaling the model size without increasing computation. This enabled the use of thousands of experts within each MoE layer. However, this setup introduces challenges. While large batch sizes usually improve performance, MoEs effectively reduce batch sizes as data flows through only the activated experts. For example, in a batch of 10 tokens, five tokens might go to one expert, while the other five are split among different experts. This results in uneven batch sizes and potential underutilization.
Notably, work from Shazeer et al. in 2017 (https://arxiv.org/abs/1701.06538) scaled the concept to very large models (e.g., a 137B parameter LSTM) by introducing sparsity, which paved the way for subsequent developments like the Switch Transformers and even multi-trillion parameter models.
To address this, a learned gating network (G) determines which experts (E) handle each part of the input:
\[ y = \sum_{i=1}^{n} G(x)_i E_i(x) \]
This setup allows weighted computation across all experts. However, if G is 0 for certain experts, their computations can be skipped, saving resources.
A typical gating function follows:
\[ G_\sigma(x) = \text{Softmax}(x \cdot W_g) \]
where W_g is a learned parameter matrix. This helps the network learn optimal routing for input tokens.
Shazeer also introduced Noisy Top-k Gating, which adds noise to improve load balancing:
-
Introduce noise:
\[ H(x)_i = (x \cdot W_g)_i + \text{StandardNormal()} \cdot \text{Softplus}((x \cdot W_{noise})_i) \]
-
Select top k experts:
\[ \text{KeepTopK}(v, k)_i = \begin{cases} v_i & \text{if } v_i \text{ is in the top } k \text{ elements of } v, \\ -\infty & \text{otherwise}. \end{cases} \]
-
Apply softmax for final gating:
\[ G(x) = \text{Softmax}(\text{KeepTopK}(H(x), k)) \]
By setting k to a low value (e.g., one or two), MoEs achieve faster training and inference while maintaining efficiency. Selecting at least two experts per token was originally hypothesized to help the gating network learn optimal routing strategies. The Switch Transformers section will revisit this decision.
The addition of noise is crucial for load balancing, ensuring that different experts receive a fair share of tokens instead of overloading a few while underutilizing others.
Load Balancing Tokens in Mixture-of-Experts (MoEs)
When training MoEs, it’s crucial to distribute tokens evenly among
experts. If most tokens are routed to only a few popular experts,
training becomes inefficient. Typically, the gating network tends to
favor a small subset of experts. This creates a self-reinforcing
cycle: the favored experts train faster and, in turn, are selected
even more often. To counteract this imbalance, an auxiliary loss is
added to the training objective. This loss encourages each expert to
process a roughly equal number of tokens. In transformer
implementations, you can control this behavior using the
aux_loss parameter. Later sections will also discuss the
notion of expert capacity—the threshold that limits the number of
tokens an expert can process.
MoEs and Transformers
Transformers have clearly demonstrated that scaling up the number of parameters can improve performance. Inspired by this success, Google explored scaling transformers well beyond 600 billion parameters with their GShard project.
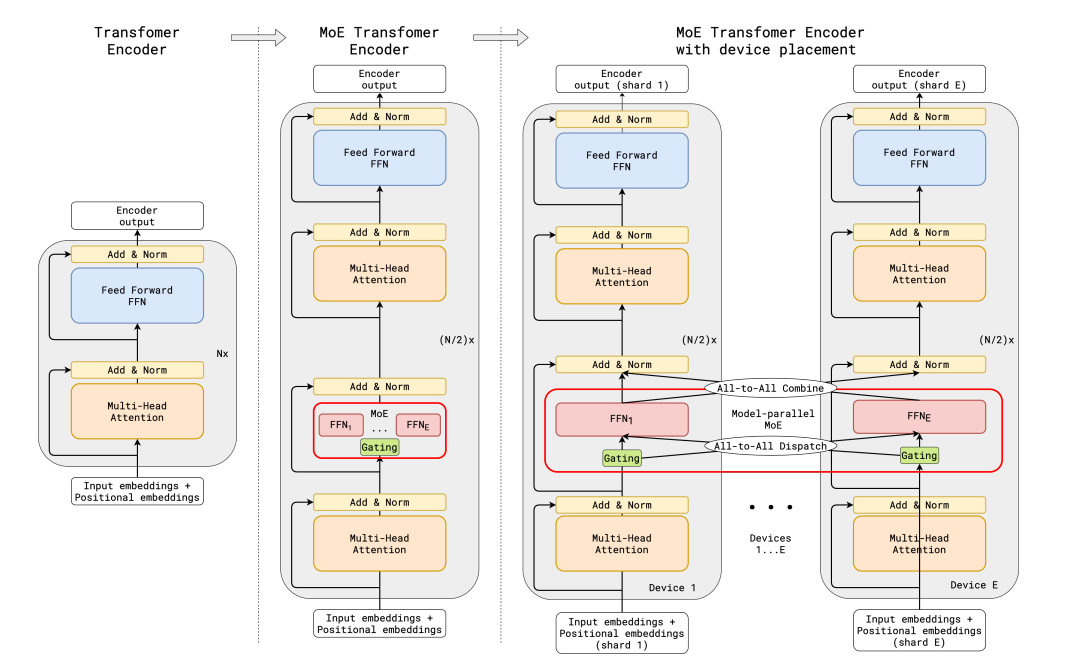
In GShard, every other Feed-Forward Network (FFN) layer is replaced by an MoE layer that uses a top-2 gating mechanism in both the encoder and decoder. (The diagram below illustrates the encoder configuration.) This design is especially beneficial for large-scale computing because while most layers are replicated across devices, the MoE layer is shared. More details on the distributed setup are discussed in the “Making MoEs go brrr” section.
The GShard MoE Transformer Encoder
To ensure balanced load distribution and efficiency, the GShard authors introduced two key modifications alongside the auxiliary loss:
- Random Routing: In a top-2 setup, the primary expert is always selected, while the second expert is chosen with a probability proportional to its weight.
- Expert Capacity: A fixed threshold limits the number of tokens each expert can process. If an expert reaches its capacity, any additional tokens are treated as overflow. These overflow tokens can either be forwarded to the next layer via residual connections or dropped, depending on the implementation. This concept is critical because tensor shapes are statically determined at compilation time, so a capacity factor must be set in advance.
While the GShard paper also describes advanced parallel computation patterns for MoEs, that discussion is beyond the scope of this post.
During inference, only a subset of experts is activated. However, some operations—like self-attention—are applied to all tokens. For example, although a 47B-parameter model with 8 experts using top-2 routing might nominally engage 14B parameters, shared computations (such as attention) mean that the effective parameter usage is closer to 12B.
Switch Transformers
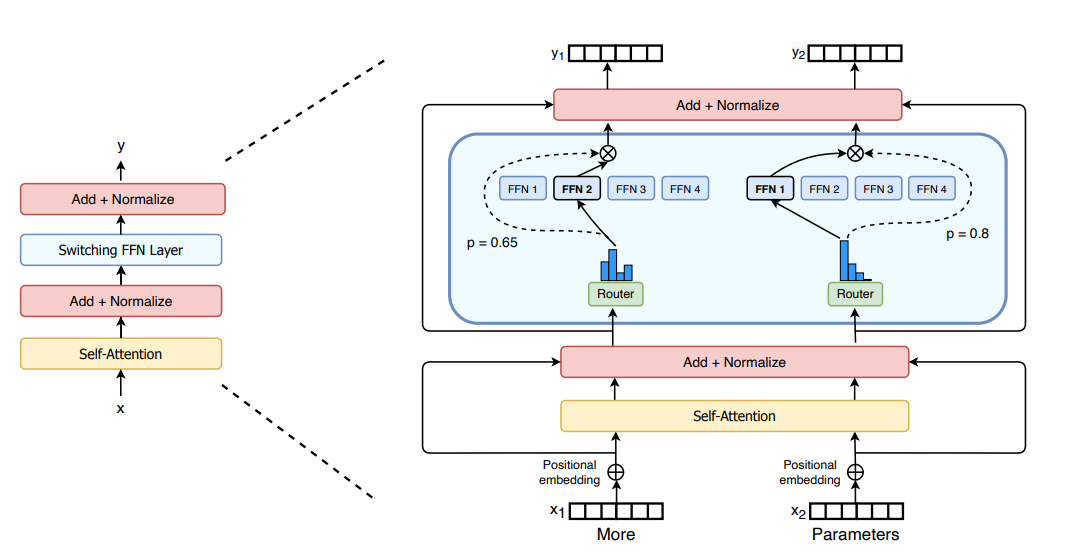
Despite their potential, MoEs can suffer from training and fine-tuning instabilities. Switch Transformers address these challenges with a streamlined approach. In one notable instance, the authors released a 1.6 trillion parameter MoE with 2048 experts on Hugging Face, demonstrating a 4× speed-up in pre-training compared to T5-XXL.
Switch Transformers also replace FFN layers with MoE layers but simplify the routing strategy by selecting only one expert per token rather than using a top-2 approach. This simplification leads to several benefits:
- Reduced router computation
- Smaller batch sizes per expert (roughly half)
- Lower communication overhead between devices
- Preservation of overall model quality
As with GShard, expert capacity remains an essential concept.
Expert Capacity in Switch Transformers:
\[ \text{Expert Capacity} = \left(\frac{\text{tokens per batch}}{\text{number of experts}}\right) \times \text{capacity factor} \]
This calculation evenly distributes tokens across experts. A capacity factor greater than 1 provides a buffer to accommodate imbalances. However, increasing the capacity factor also increases inter-device communication costs, so it must be chosen carefully. Experiments with Switch Transformers have shown strong performance using capacity factors in the range of 1–1.25. Additionally, Switch Transformers incorporate a load balancing (auxiliary) loss at each layer. This loss, weighted by a hyperparameter, encourages uniform token routing and is added to the overall model loss during training. The Switch Transformers paper also investigates selective precision—training the experts in bfloat16 while keeping other computations in full precision. This strategy reduces memory usage, computation time, and communication overhead. Early experiments using bfloat16 for both experts and gating networks encountered instability, particularly because the router’s exponential operations are sensitive to precision. Switching the routing computations to full precision alleviated these issues without degrading model quality.
The Fine-tuning Switch Transformers Notebook demonstrates how to fine-tune Switch Transformers for summarization tasks.
Switch Transformers use an encoder-decoder setup similar to T5. Meanwhile, the GLaM paper (https://arxiv.org/abs/2112.06905) extends these ideas by focusing on decoder-only models and few-shot/one-shot evaluations. GLaM achieves GPT-3–comparable quality while using only about one-third of the training energy, thanks in part to top-2 routing and larger capacity factors. Moreover, the authors explore dynamically adjusting the capacity factor during training and evaluation, offering another lever to balance computational efficiency and performance.
How Do Experts Specialize?
The authors of ST-MoE observed that encoder experts tend to specialize in groups of tokens or shallow linguistic concepts. For example, an expert might focus on punctuation, while another specializes in proper nouns. In contrast, decoder experts exhibit less specialization.
In a multilingual setup, one might expect experts to specialize in different languages. However, due to token routing and load balancing, no single expert becomes dedicated to a specific language. Instead, experts specialize in token groups across multiple languages.
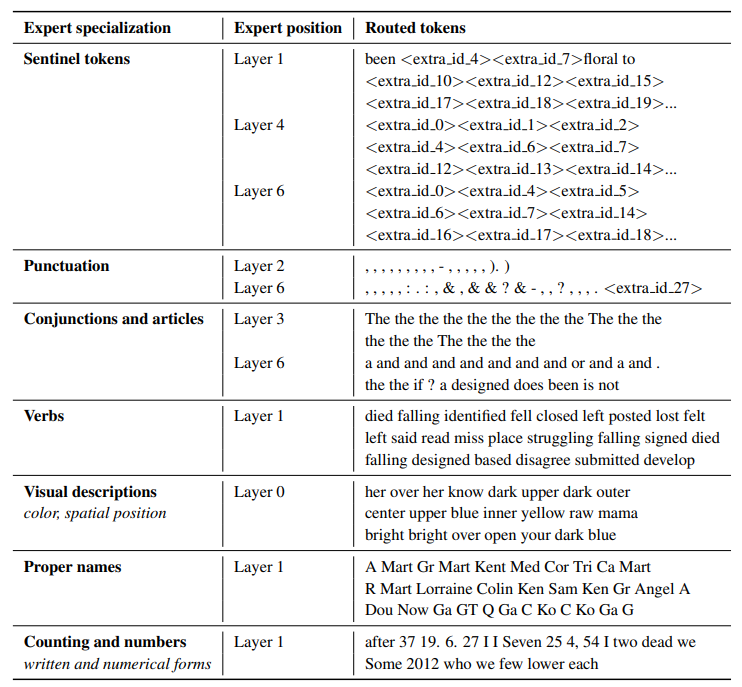
Increasing the number of experts improves sample efficiency and accelerates training. However, the benefits diminish beyond 256 or 512 experts, and inference requires more VRAM. Studies on Switch Transformers show that MoE properties observed at large scales remain consistent even with as few as 2, 4, or 8 experts per layer.
Fine-Tuning Sparse MoEs
Sparse models behave differently during fine-tuning compared to dense models:
- They overfit more easily, requiring higher regularization (e.g., dropout).
- Different dropout rates may be needed for dense layers vs. sparse layers.
- The auxiliary loss (used in training MoEs) may not be necessary during fine-tuning. ST-MoE authors found that disabling it did not significantly impact quality, even when up to 11% of tokens were dropped—suggesting token dropping itself acts as a form of regularization.
Performance differences between Sparse vs. Dense Models:
- Sparse models perform worse on reasoning-heavy tasks (e.g., SuperGLUE) but excel in knowledge-heavy tasks (e.g., TriviaQA).
- Sparse models also struggle on smaller tasks but generalize well in larger tasks.
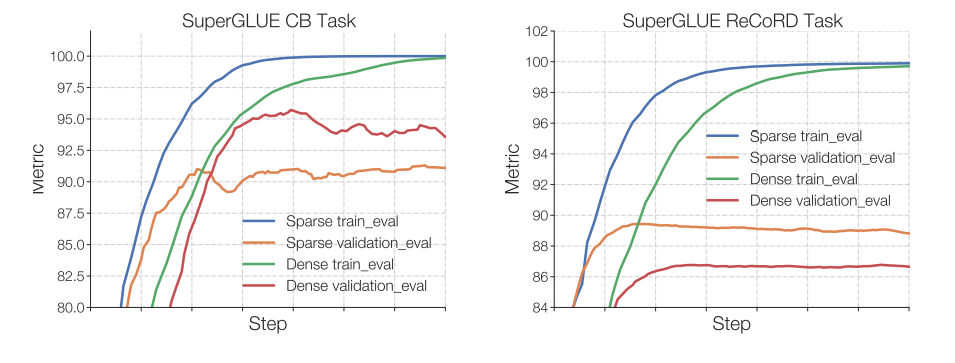
One could experiment with freezing all non-expert weights:
- Freezing all non-expert weights (updating only MoE layers) leads to poor performance.
- Freezing only the MoE layers (updating everything else) preserves quality while reducing memory usage and speeding up fine-tuning.
- This is counterintuitive since MoE layers contain 80% of the parameters, yet updating them affects far fewer layers than updating the dense backbone.

One last part to consider when fine-tuning sparse MoEs is that they have different fine-tuning hyperparameter setups - e.g., sparse models tend to benefit more from smaller batch sizes and higher learning rates.
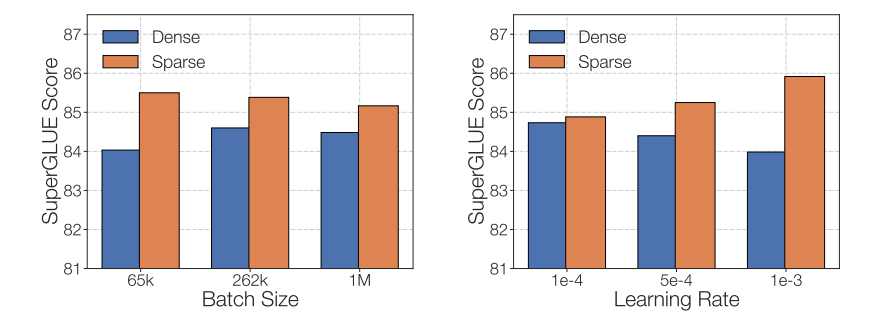
Despite fine-tuning challenges, a 2023 paper, MoEs Meet Instruction Tuning (https://arxiv.org/pdf/2305.14705.pdf), explored three setups:
- Single-task fine-tuning
- Multi-task instruction tuning
- Multi-task instruction tuning followed by single-task fine-tuning
Key Findings:
- When fine-tuned directly, the MoE performed worse than its dense T5 equivalent.
- However, when Flan T5 (an instruction-tuned version) was used, the MoE significantly outperformed its dense counterpart.
- MoEs benefit more from instruction tuning than dense models, with improvements larger than those seen in dense models like T5.
- Unlike previous findings suggesting the auxiliary loss could be disabled, instruction tuning showed that keeping it helps prevent overfitting.
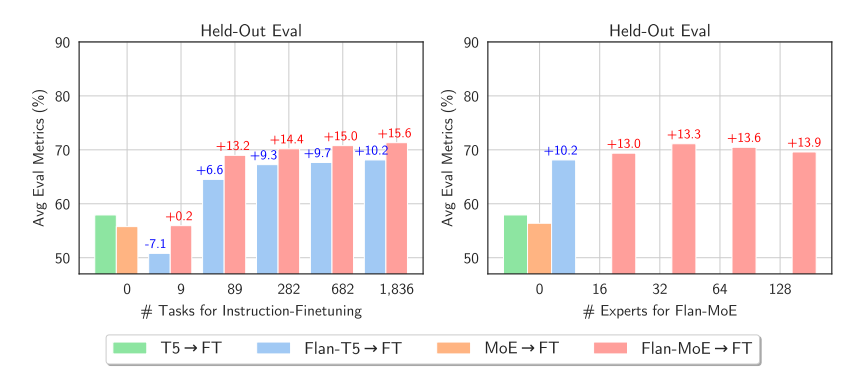
When to Use Sparse MoEs vs. Dense Models?
- Sparse MoEs are ideal for high-throughput scenarios with access to multiple machines. They are more compute-efficient for pretraining.
- Dense models are preferable in low-throughput environments with limited VRAM.
Important Note: Comparing parameter counts between sparse and dense models is misleading, as their architectures function differently.
Source: https://huggingface.co/blog/moe
6.3 How to build a production-grade RAG system, explain each component in detail?▼
Retrieval-Augmented Generation (RAG) is a powerful AI architecture that enhances generative models by integrating an external knowledge base. A production-grade RAG system requires efficient indexing, retrieval, and generation pipelines, ensuring scalability, accuracy, and reliability.
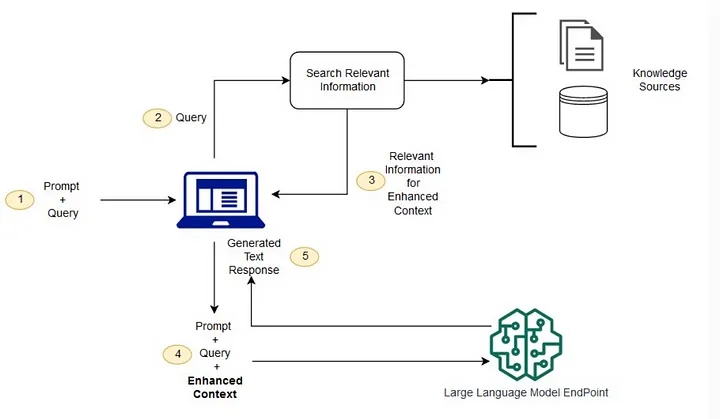
The RAG Workflow consists in three key pipelines:
1. Indexing Pipeline: Building Your Knowledge Base
The indexing pipeline is responsible for gathering, processing, and storing data in a format optimized for retrieval. Key components:
- Connectors: Extract data from multiple sources such as databases, object storage (e.g., Amazon S3), websites, and SaaS applications.
- Data Loaders: Format extracted data into a structured or semi-structured format (e.g., JSON, XML, SQL tables).
- Processors: Extract meaningful content from various document formats, including PDFs, images, and scanned texts.
- Data Security (PII Handling): Ensure privacy compliance by redacting or anonymizing sensitive information before indexing.
- Document Chunking: Break large documents into smaller segments to improve retrieval accuracy while maintaining context.
- Enrichment: Add metadata (e.g., tags, timestamps, source identifiers) to documents for improved filtering and retrieval.
- Embedding Models: Convert text into vector representations using models like OpenAI embeddings, BERT, or SBERT.
- Vector Optimization: Apply techniques like dimensionality reduction and quantization for efficiency.
- Indexing: Store vectorized data in a high-performance vector database (e.g., FAISS, Pinecone, OpenSearch).
Considerations:
- Managed vs. Self-Hosted: Decide between a managed database service (e.g., AWS OpenSearch, Pinecone) or an in-house deployment.
- Search Speed vs. Recall: Optimize for speed and accuracy depending on application requirements.
- Cost & Security: Evaluate storage costs and security measures when handling enterprise data.
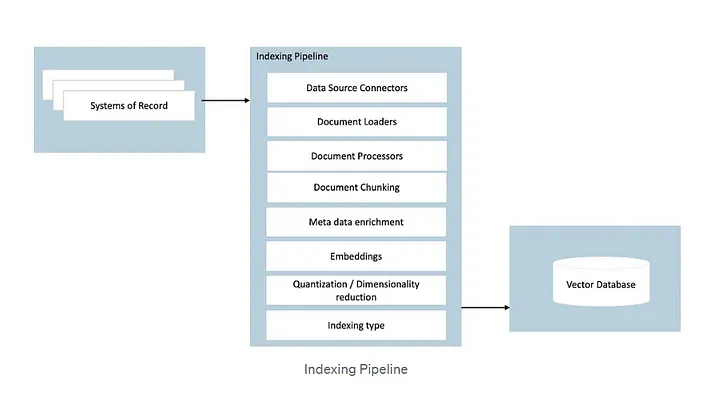
2. Retrieval Pipeline: Searching for Relevant Information
Once the knowledge base is indexed, the retrieval pipeline identifies and returns the most relevant document chunks based on a user's query. Key components:
- Retrievers: Perform similarity search using vector-based, keyword-based, or hybrid retrieval approaches.
- Filters: Leverage metadata to refine search results based on criteria such as document type, date, or source.
- Re-ranking: After retrieving the initial set of documents, you may need to re-rank them based on relevance. This ensures that only the best-matching chunks are passed on to the generation pipeline.
- Data Optimization: Remove duplicate or irrelevant results to improve response accuracy.
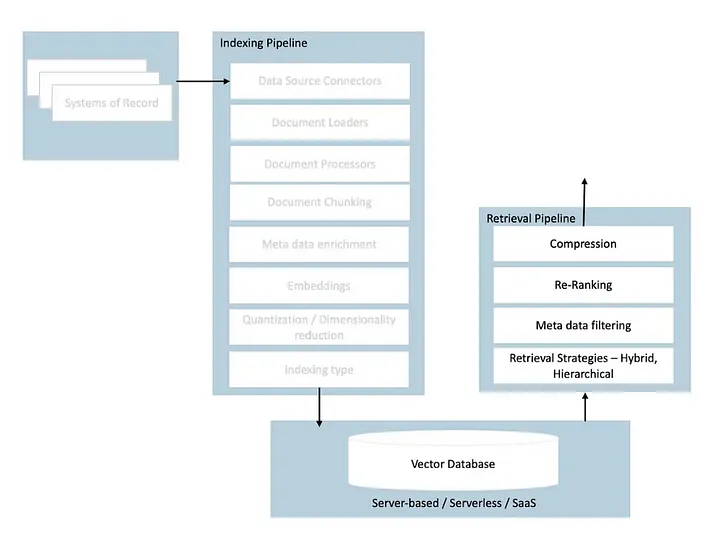
3. Generation Pipeline: Producing the Final Output
The generation pipeline processes retrieved information and generates a final response tailored to the user's query. Key components:
- Caching: Implement caching mechanisms (e.g., Amazon MemoryDB for Redis) to reduce redundant retrievals and speed up responses.
- Guardrails: Apply safety filters to prevent biases, toxicity, or hallucinations in generated responses.
- Session Management: Maintain conversational context across user interactions for improved response coherence.
- Response Formatting: Format responses in JSON, XML, Markdown, or structured formats suitable for different applications.
- Moderation: Incorporate human-in-the-loop moderation for critical use cases requiring quality control.
AWS provides multiple services to simplify RAG system development:
- Amazon Bedrock: Offers pre-built generative AI models and integration with vector databases.
- Amazon OpenSearch: Enables scalable vector search, metadata filtering, and integration with Amazon SageMaker.
- Amazon S3: Stores unstructured data and serves as a scalable data lake for knowledge bases.
- AWS Lambda & SageMaker: Support on-demand processing, embedding generation, and fine-tuning of retrieval models.
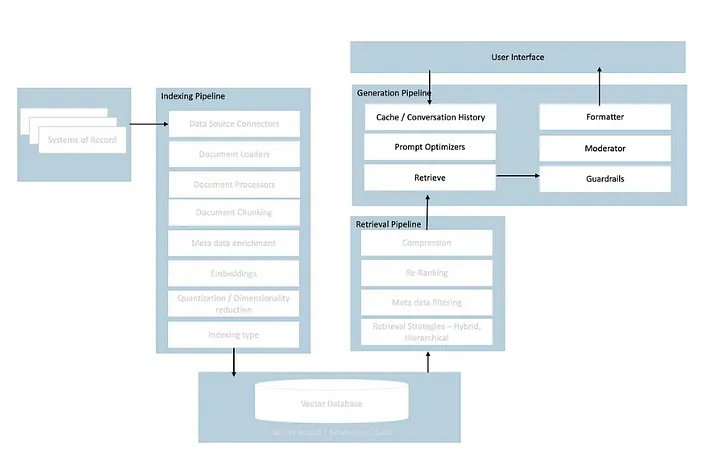
Several open-source libraries can be used to build modular RAG systems:
- LangChain: Provides tools for chaining together retrieval and generation steps.
- LlamaIndex: Focuses on efficient document chunking and indexing.
- Haystack: Offers end-to-end RAG implementations with support for multiple databases.
6.4 What is FP8 variable and what are its advantages? How to train LLM with low precision training without compromising on accuracy?▼
FP8 (8-bit floating point) is a new datatype introduced with the NVIDIA H100 GPU, designed to improve computational efficiency in deep learning training. It consists of two formats:
- E4M3 (1 sign bit, 4 exponent bits, 3 mantissa bits) – Used in the forward pass as it offers better precision.
- E5M2 (1 sign bit, 5 exponent bits, 2 mantissa bits) – Used in the backward pass due to its higher dynamic range.

During training neural networks both of these types may be utilized. Typically forward activations and weights require more precision, so E4M3 datatype is best used during forward pass. In the backward pass, however, gradients flowing through the network typically are less susceptible to the loss of precision, but require higher dynamic range. Therefore they are best stored using E5M2 data format. H100 TensorCores provide support for any combination of these types as the inputs, enabling us to store each tensor using its preferred precision.
To understand how FP8 enhances deep learning training, it's helpful to first review mixed precision training with FP16. Mixed precision training combines lower-precision computations with higher-precision storage to optimize performance while maintaining accuracy.
FP16 training relies on two key techniques:
- Selecting FP16 Operations – Operations like matrix multiplications, convolutions, and normalization layers benefit from FP16, while others (e.g., norm and exp functions) require higher precision.
- Dynamic Loss Scaling – FP16 has a limited dynamic range, which can lead to overflows or underflows in gradient values. Dynamic loss scaling adjusts the scale of gradients to keep them within a representable range without affecting numerical accuracy.
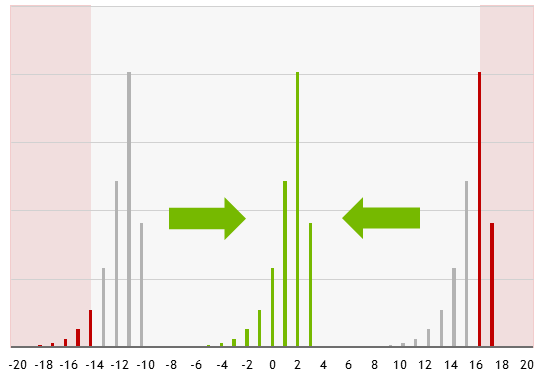
FP8 offers sufficient dynamic range for individual activations and gradients but not for all simultaneously. This limitation makes the single loss scaling factor used in FP16 training unsuitable, requiring distinct scaling factors for each FP8 tensor.
FP8 Scaling Strategies
- Just-in-Time Scaling – Determines the scaling factor based on the maximum absolute value (amax) of the tensor after computation. However, this method introduces excessive overhead, reducing FP8's efficiency.
- Delayed Scaling – Uses the maximum absolute values observed over multiple iterations to determine the scaling factor. This approach maintains FP8's performance but requires storing and updating historical amax values.
Source: https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/examples/fp8_primer.html
6.5 How to calculate the size of the KV cache? ▼
The KV (Key-Value) cache stores intermediate activations for faster autoregressive decoding in transformers.
The size of the KV cache depends on:
- Number of layers (\(L\))
- Sequence length (\(S\)) (max tokens stored)
- Number of key-value heads (\(H_k\))
- Head size (\(D_h\)) (Hidden size / Attention heads)
- Precision (\(dtype\_size\)) (bytes per parameter: FP16 = 2 bytes, BF16 = 2 bytes, FP32 = 4 bytes)
The formula for KV Cache Size is:
\[ \text{KV Cache Size} = 2 \times L \times S \times H_k \times D_h \times dtype\_size \]
The factor 2 accounts for both the key (K) and value (V) caches.
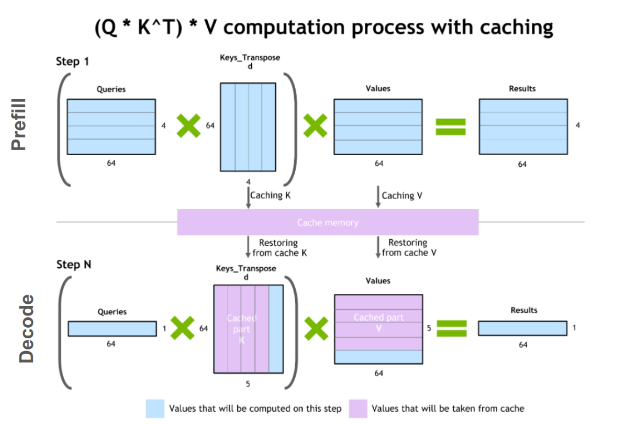
Example Calculation for DeepSeek-V3 model:
- Hidden Size: 7168
- Number of Attention Heads: 128
- Number of Hidden Layers (\(L\)): 61
- Number of Key-Value Heads (\(H_k\)): 128
- Head Size (\(D_h\)): 56 (Hidden Size / Attention Heads)
- \(dtype\_size\): 2 bytes (FP16)
- Sequence Length (S): 10,000 tokens (assumed cache length)
Step-by-Step Calculation:
1. Compute the Total Elements in KV Cache
\[ \text{Total Elements} = 2 \times L \times S \times H_k \times D_h \] \[ = 2 \times 61 \times 10000 \times 128 \times 56 \] \[ = 8,744,960,000 \text{ elements} \]
2. Convert to Bytes
\[ \text{Total Bytes} = \text{Total Elements} \times dtype\_size \] \[ = 8,744,960,000 \times 2 \] \[ = 17,489,920,000 \text{ bytes} \]
3. Convert to GB
\[ \text{KV Cache Size} = \frac{\text{Total Bytes}}{1024^3} \] \[ \approx 16.2888 \text{ GB} \]
6.6 Explain the dimension of each layer in a multi-headed transformation attention block. ▼
A multi-headed self-attention (MHSA) block is a key component in the Transformer architecture. Below is a breakdown of the dimensions at each step of a multi-headed attention block:
Let the input to the Transformer be: \[ X \in \mathbb{R}^{(B, T, d_{\text{model}})} \] where:
- \( B \) = batch size
- \( T \) = sequence length (number of tokens)
- \( d_{\text{model}} \) = embedding dimension of each token
1. Linear Projection to Query, Key, and Value
Each input token \( X \) is projected into three matrices: Query (Q), Key (K), and Value (V) using learned weight matrices: \[ Q = XW_Q, \quad K = XW_K, \quad V = XW_V \] where:
- \( W_Q, W_K, W_V \in \mathbb{R}^{(d_{\text{model}}, d_{\text{k}})} \)
Thus, their dimensions are: \[ Q, K, V \in \mathbb{R}^{(B, T, d_{\text{k}})} \] where \( d_{\text{k}} \) is typically set to \( d_{\text{model}}/h \) (i.e., head dimension).
2. Splitting into Multiple Heads
In multi-headed attention, we split \( Q, K, V \) into \( h \) different heads. If \( d_{\text{model}} \) is the embedding dimension and \( h \) is the number of heads, then: \[ d_{\text{k}} = d_{\text{model}} / h \] So, after splitting into heads, the dimensions of each matrix become: \[ Q, K, V \in \mathbb{R}^{(B, h, T, d_{\text{k}})} \] Each head operates independently.
3. Scaled Dot-Product Attention
Each attention head computes: \[ \text{Attention}(Q, K, V) = \text{softmax} \left(\frac{QK^T}{\sqrt{d_{\text{k}}}} \right) V \]
- \( QK^T \) results in a score matrix of shape \( \mathbb{R}^{(B, h, T, T)} \).
- After softmax and multiplication with \( V \), the output shape remains: \[ \mathbb{R}^{(B, h, T, d_{\text{k}})} \]
4. Concatenation of Attention Heads
The output from each of the \( h \) heads is concatenated back: \[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h) \] Since each head has an output of \( \mathbb{R}^{(B, T, d_{\text{k}})} \), concatenating all \( h \) heads results in: \[ \mathbb{R}^{(B, T, h \cdot d_{\text{k}})} \] Since \( h \cdot d_{\text{k}} = d_{\text{model}} \), the final output after concatenation is: \[ \mathbb{R}^{(B, T, d_{\text{model}})} \]
5. Final Linear Transformation
A learned weight matrix \( W_O \) is applied to project the concatenated output back to the model dimension: \[ \text{Output} = (\text{MultiHead}(Q, K, V)) W_O \] where: \[ W_O \in \mathbb{R}^{(d_{\text{model}}, d_{\text{model}})} \] Thus, the final output has the same shape as the input: \[ \mathbb{R}^{(B, T, d_{\text{model}})} \]
6.7 How do you make sure that the attention layer focuses on the right part of the input?▼
Positional Encoding: Transformers lack inherent sequence information, so positional encodings are added to the input embeddings to provide information about the position of each token in the sequence. This helps the model understand the order and relative positions of tokens.
import torch
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
Attention Mechanism: The self-attention mechanism allows the model to weigh the importance of different tokens in the input sequence when generating the representation for a particular token. This helps the model focus on relevant parts of the input.
Select the right type of attention mechanism based on the task requirements:
- Self-Attention: For understanding dependencies within a sequence (e.g., Transformers).
- Cross-Attention: For aligning different inputs (e.g., in multimodal models like image-captioning).
- Soft vs. Hard Attention: Soft attention assigns weights continuously, while hard attention forces discrete focus (requires reinforcement learning).
import torch.nn.functional as F
def scaled_dot_product_attention(query, key, value, mask=None):
matmul_qk = torch.matmul(query, key.transpose(-2, -1))
dk = key.size()[-1]
scaled_attention_logits = matmul_qk / torch.sqrt(torch.tensor(dk, dtype=torch.float32))
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = F.softmax(scaled_attention_logits, dim=-1)
output = torch.matmul(attention_weights, value)
return output, attention_weights
Multi-Head Attention: Multi-head attention allows the model to attend to different parts of the input simultaneously. Each head learns to focus on different aspects of the input, providing a richer representation.
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model)
def split_heads(self, x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.depth)
return x.permute(0, 2, 1, 3)
def forward(self, v, k, q, mask):
batch_size = q.size(0)
q = self.split_heads(self.wq(q), batch_size)
k = self.split_heads(self.wk(k), batch_size)
v = self.split_heads(self.wv(v), batch_size)
scaled_attention, _ = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = scaled_attention.permute(0, 2, 1, 3).contiguous()
original_size_attention = scaled_attention.view(batch_size, -1, self.d_model)
output = self.dense(original_size_attention)
return output
Masking: In tasks like language modeling, where the model should not attend to future tokens, masking is used to prevent the attention mechanism from considering certain positions. This ensures that the model only focuses on the appropriate parts of the input.
def create_mask(size):
mask = torch.tril(torch.ones(size, size))
return mask
mask = create_mask(5)
print(mask)
Layer Normalization: Layer normalization helps stabilize the training process and ensures that the attention mechanism focuses on the right parts of the input by normalizing the inputs to each layer.
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(features))
self.beta = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.eps) + self.beta